The adoption of artificial intelligence (AI) technologies, such as ChatGPT, has surged dramatically, propelling the market capitalization of Nvidia (AI hardware manufacturer) to over $3.3 trillion and establishing it as the world's largest company in July 2024. Looking ahead, global investment in AI technologies is projected to reach $200 billion by 2025, underscoring the expanding role of AI across various industries. Generative AI (GenAI) has become a central focus, accounting for 48% of total AI funding in 2023—a significant rise from just 8% in 2022.
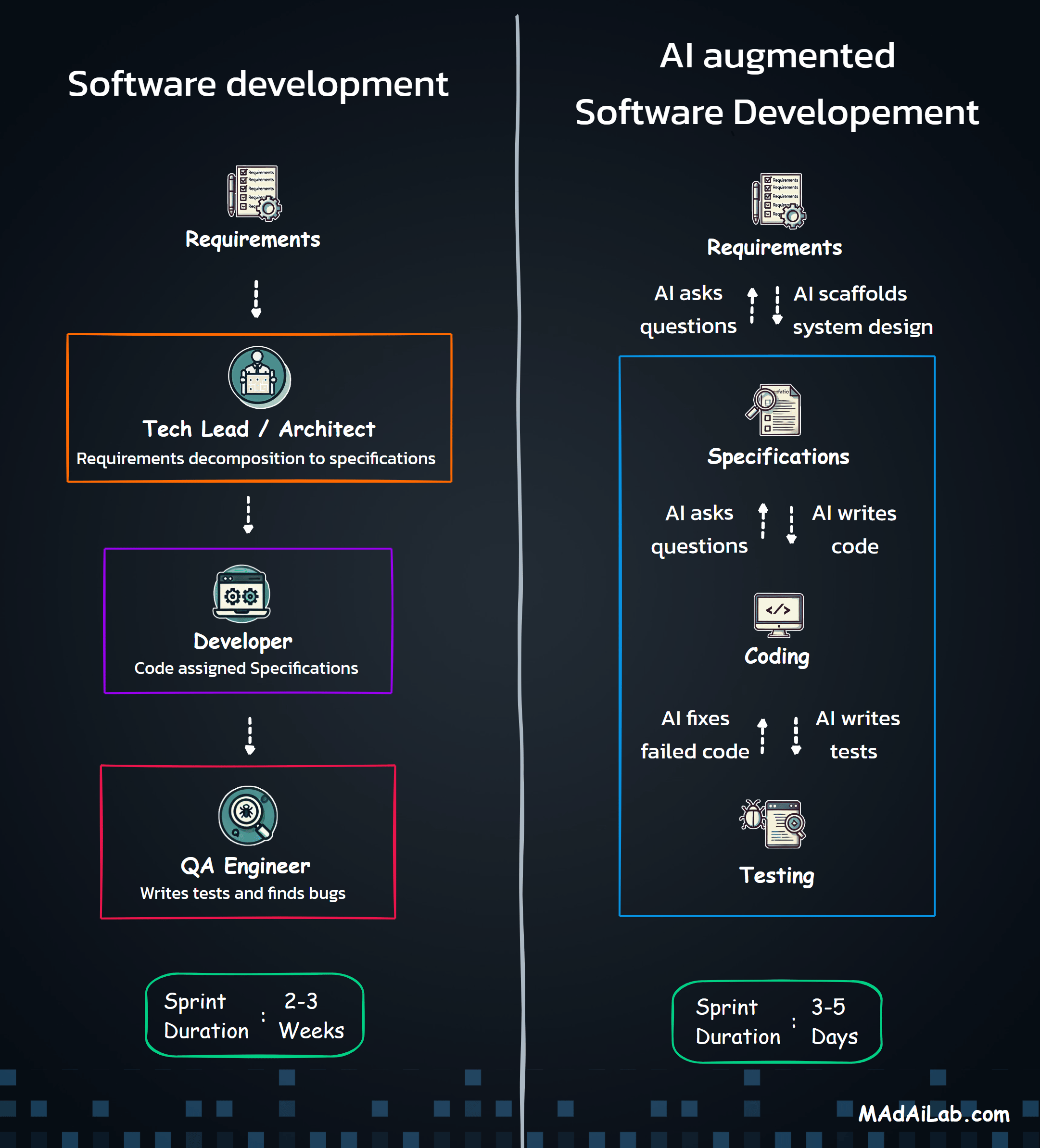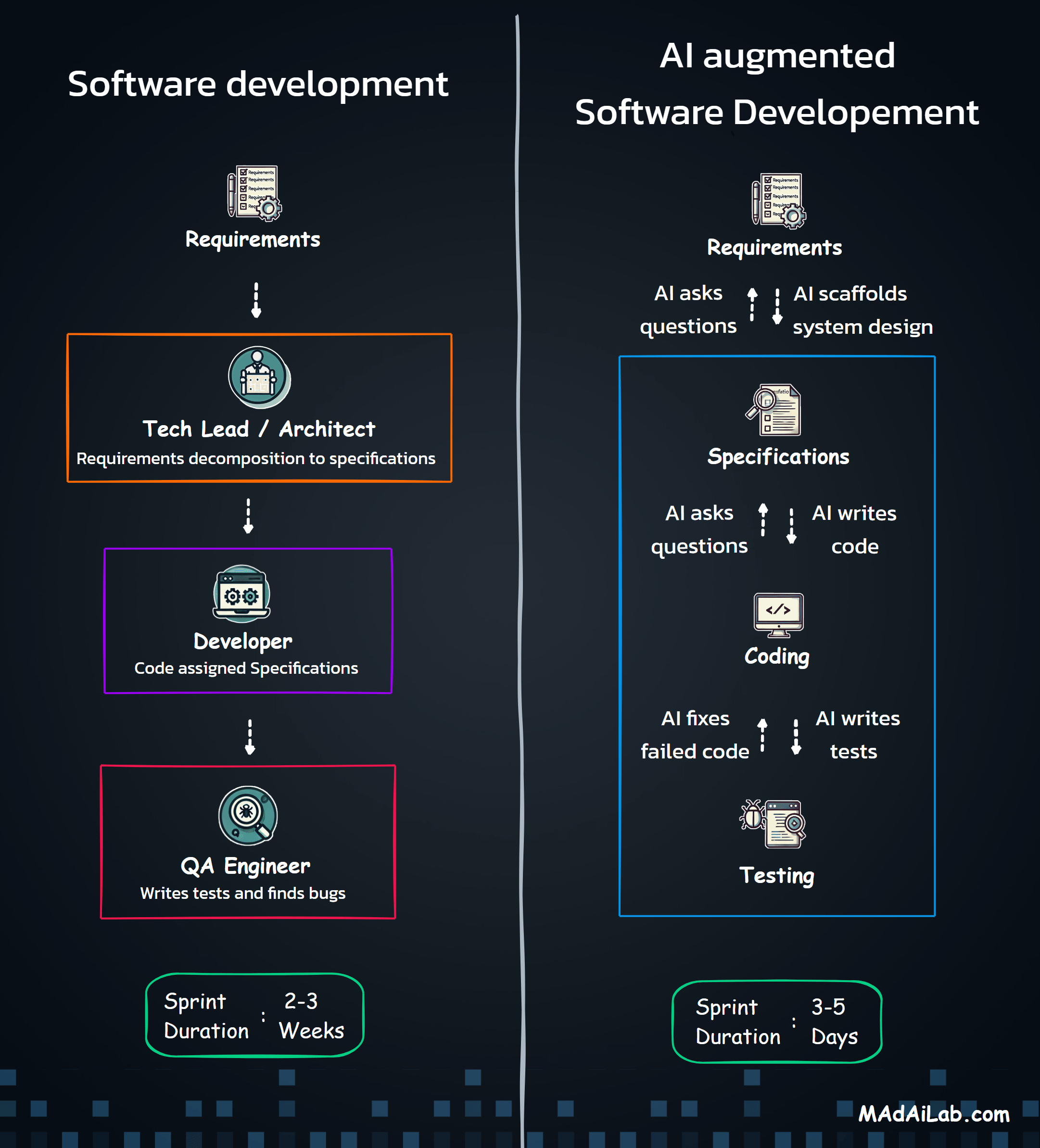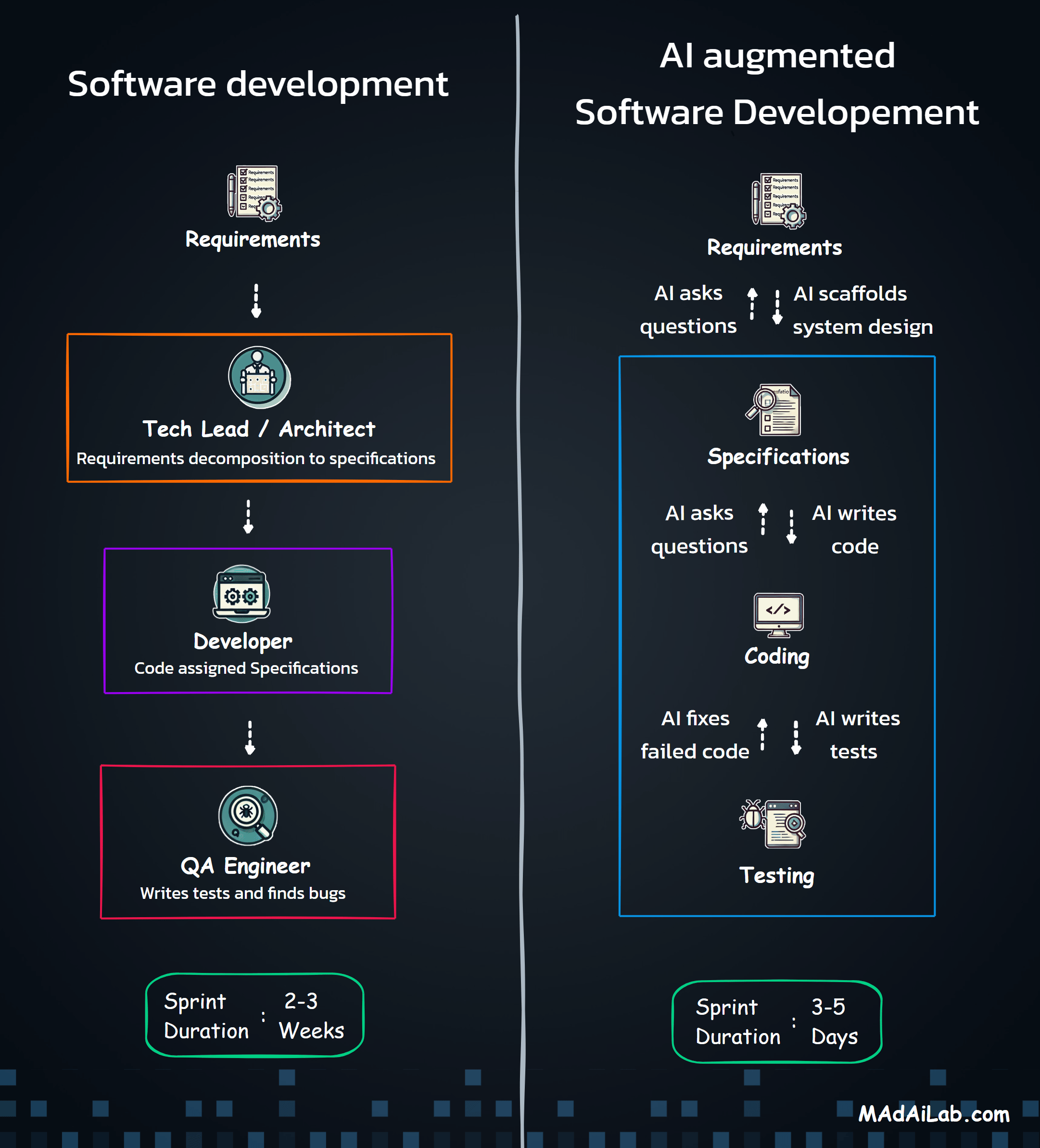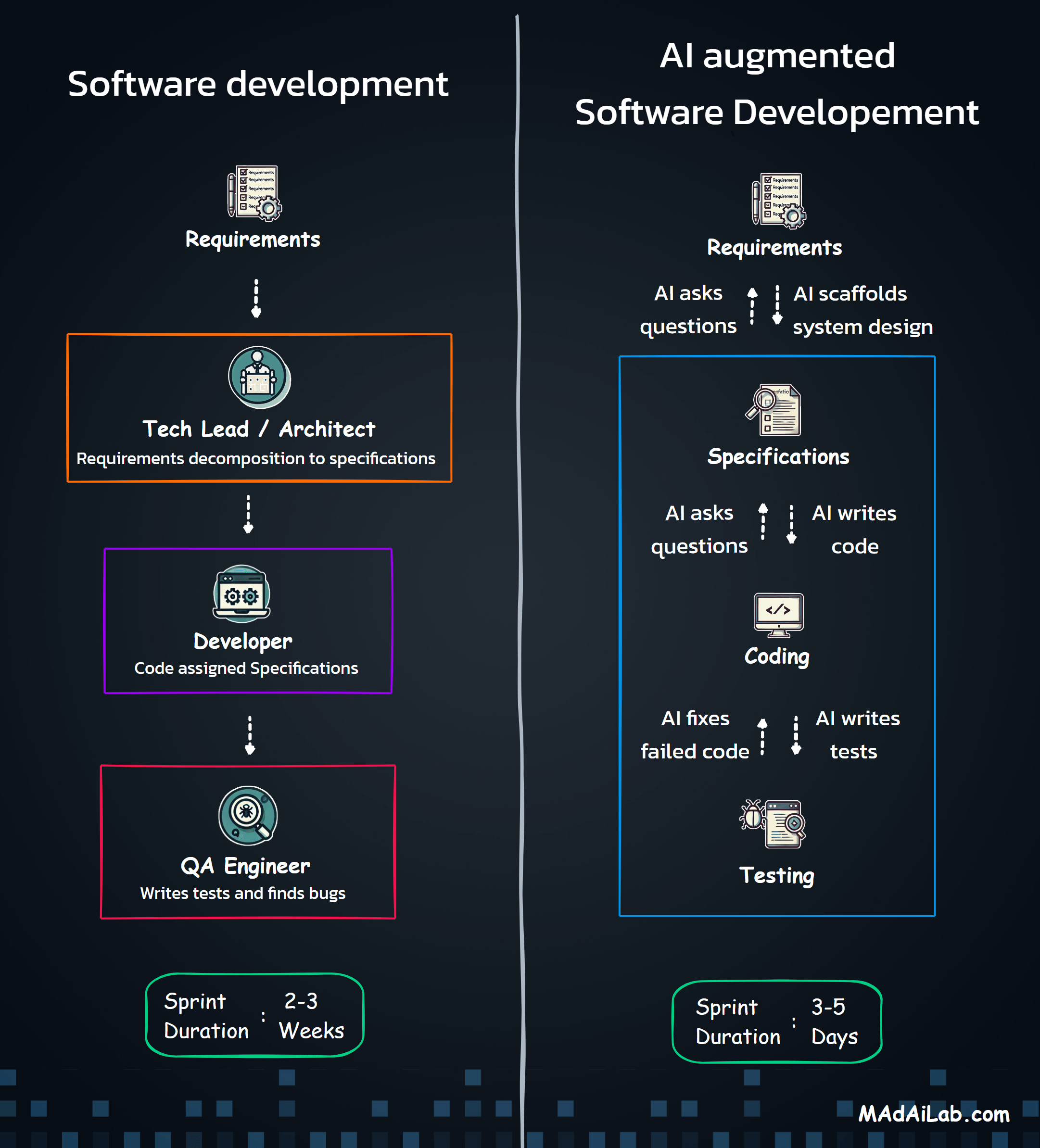
Until the last decade, much of what was popularly considered Artificial Intelligence (AI) was dominated by traditional machine learning (ML) methods such as regression, support vector machines (SVMs), random forests, and XGBoost. These methods excelled in many applications and were particularly well-suited to structured data—tabular datasets with defined numerical or categorical features. Traditional ML typically follows a structured pipeline with well-defined steps as shown in the first part of the diagram: data gathering, feature engineering, model training, and deployment. They performed remarkably well for tasks such as classification (e.g., predicting categories) or regression (e.g., forecasting numbers). Applications like recommender systems and predictive analytics flourished using these techniques.
However, traditional ML had limitations when applied to tasks involving unstructured data like text, images, or audio. To illustrate, consider a social media manager tasked with choosing an image for a blog article. This process might involve:
Traditional ML approaches could extract keywords or classify images to some extent, but required extensive feature engineering, significant human effort and expertise for feature engineering and often resulted in subpar performance. This was a major reason why many creative, human-centric tasks remained difficult to automate.
The emergence of deep learning and, more recently, Generative AI (GenAI), has transformed how AI tackles such challenges. Deep learning models handle unstructured data like text, images, audio and video in a way that traditional ML could not. These models learn to extract complex patterns directly from raw data, effectively eliminating the need for manual feature engineering. GenAI models can be highly useful for assisting with parts of human decision making, especially those involving text/image generation, summarization, answering question based on context, extracting keywords as per instructions, etc.).
This fundamental shift in capabilities has created both new opportunities and challenges. Yet despite these advances, many discussions still equate AI with traditional ML approaches, failing to recognize that GenAI is the primary driver of current enthusiasm and innovation. This oversimplification not only misrepresents the technology but also risks diverting attention from the unique challenges of GenAI. Consequently, professionals may overlook the need to address these challenges and allocate resources effectively to ensure GenAI's reliable integration into business workflows.
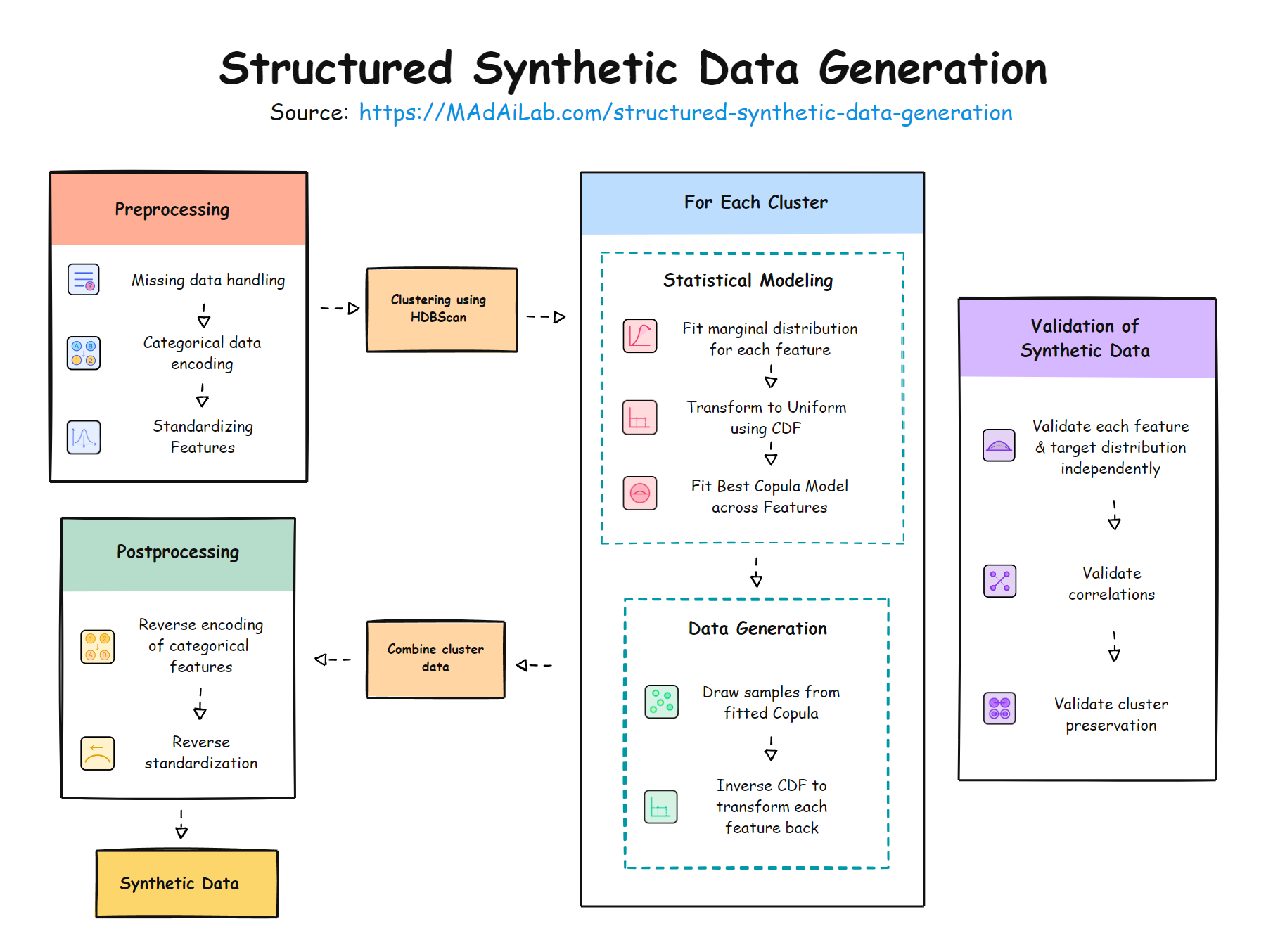
In this article, we examine the fundamental ways GenAI differs from traditional ML and explore how these distinctions necessitate workflow redesign. The accompanying flowchart provides a comprehensive visualization of a typical GenAI workflow, highlighting six key areas where it diverges from conventional ML pipelines: workflow experimentation, metrics and evaluation, guardrails, output monitoring, prompt engineering, and model drift. As the flowchart illustrates, each of these areas introduces new considerations and complexities that must be carefully managed. Below, we discuss these key differences in detail, demonstrating why organizations need to fundamentally reevaluate how they develop, guide, and deploy GenAI systems.

GenAI's capacity to simulate human decision-making enables organizations to automate complex tasks that were previously considered too nuanced for traditional automation. However, this capability introduces new challenges in workflow design and optimization, as shown in the "Workflow Experimentation" element of our flowchart.
While Generative AI (GenAI) has revolutionized certain aspects of human decision-making automation, traditional tools like coding, machine learning (ML), APIs, and database calls remain essential for other facets. Implementing GenAI effectively requires more than just leveraging its advanced capabilities; it necessitates a nuanced approach to replicating the integrated and often implicit cognitive steps humans naturally perform during decision-making.
A key aspect of GenAI workflow experimentation involves task decomposition—an essential process of unpacking what were previously fluid human cognitive processes into discrete, manageable components that can be handled by AI systems. When humans perform complex tasks, they often seamlessly integrate multiple cognitive processes without explicitly defining each step. For instance, a human editor reviewing an article simultaneously considers content accuracy, tone, audience engagement, and cultural sensitivity without consciously separating these aspects. The challenge in GenAI implementation lies in identifying and articulating these implicit cognitive steps and finding ways to replicate them through AI operations. This decomposition process often reveals multiple potential approaches to solving the same problem, each representing a different way of breaking down and reconstructing human cognitive workflows, with its own trade-offs in terms of reliability, cost, and complexity.
Consider, for example, the task of selecting an appropriate image for a blog post. This seemingly straightforward task can be approached through several workflow variations:
Similarly, in content moderation—another domain where GenAI is increasingly deployed—different workflow variations emerge:
These workflow variations illustrate why experimentation is crucial in GenAI implementation. Each approach represents a different way of decomposing the task, and the optimal choice often depends on specific use case requirements, resource constraints, and performance metrics.
This level of workflow experimentation stands in marked contrast to traditional ML approaches. Traditional machine learning (ML) models focus on specific predictive and descriptive tasks, with their architectures designed around transforming input data into well-defined output formats. Unlike generative AI models that can produce diverse forms of content, traditional ML specializes in targeted tasks like classification, regression, and pattern recognition. They are typically employed in structured environments with clearly defined inputs and outputs, where the goal is to optimize performance on specific metrics. Hence, they do not require extensive workflow experimentation, where different task decompositions and sequences need to be explored.
The flowchart illustrates this divergence by showing how GenAI workflows can branch into either prompt-based solutions or fine-tuned models, depending on the task requirements. This flexibility in approach, combined with the ability to experiment with different task decomposition strategies, allows organizations to iteratively develop and refine workflows that can handle increasingly sophisticated decision-making processes. Potential workflow sequences must be compared carefully, with the final choice balancing trade-offs across various metrics such as reliability, cost, and complexity.
Traditional ML systems rely on clear, quantitative metrics such as accuracy, mean squared error (MSE), and F1 score, which are objective and easily automated. For instance, in a customer churn prediction model, accuracy directly measures the percentage of correct predictions, while MSE quantifies the difference between predicted and actual values in tasks like sales forecasting. These metrics provide straightforward ways to assess model performance and guide improvements.
The Metrics Planning step for GenAI requires a more nuanced and multi-faceted approach. GenAI outputs, such as empathetic dialogue, error-free technical instructions, or humorous marketing copy, often require subjective evaluation that defies straightforward numerical measurement. Additionally, GenAI systems can sometimes generate plausible but factually incorrect information—a phenomenon known as hallucination—which requires specialized detection methods. This complexity necessitates three distinct types of evaluation:
These three evaluation streams converge in the Fine-Tuned Model or Prompt Chain Validation phase, where results are synthesized and compared against human expectations. When misalignments emerge—for instance, if automated metrics indicate high performance but human assessors find the outputs lacking appropriate emotional tone or cultural nuance—teams can pursue several established adjustment paths. These include revising the evaluation metrics, experimenting with different prompt chains, or modifying fine-tuning strategies. Teams can first try different metrics to better capture the desired generated output aspects. If misalignments persist, they can explore different prompt chains or models for fine-tuning. When both these approaches prove insufficient, teams can try a different workflow variation, such as trying alternative task decomposition strategies.
This comprehensive evaluation process stands in marked contrast to traditional ML approaches. In conventional ML, performance improvements typically involve straightforward parameter tuning, algorithm selection, or feature engineering. GenAI evaluation, however, requires a more sophisticated approach that balances multiple feedback loops and assessment types. This multi-layered system helps ensure not only technical accuracy and the absence of hallucination, but also the subjective qualities that make GenAI outputs truly valuable.
Following the careful design of workflows, implementing robust pre-generative guardrails becomes essential for responsible GenAI deployment. As shown in the flowchart's Query Processing section, these guardrails serve as a critical checkpoint before any user query reaches the AI system, with clear "Pass" and "Reject" decision paths.
Unlike traditional ML systems that operate within tightly controlled environments, GenAI models face dynamic, user-driven interactions that require comprehensive protective measures. These pre-generative guardrails evaluate incoming queries through several key security and safety lenses:
The flowchart illustrates how these guardrails operate in practice through a binary decision process:
Consider a practical example: In a customer service AI system, incoming queries first pass through these guardrails. If a user asks for help with a product return, the query passes through. However, if they request confidential information about other customers, the system would reject the query and inform the user about data privacy policies.
These pre-generative guardrails work in concert with the broader workflow shown in the flowchart, forming the first line of defense in a comprehensive safety framework.

The monitoring phase in GenAI deployment introduces unique operational challenges that go beyond traditional ML's focus on system performance and data drift detection. To address these challenges, organizations rely on random sampling and human evaluation of production outputs as a cornerstone of their monitoring strategy. This approach enables teams to detect subtle quality issues, validate metric effectiveness, and identify potential degradations that automated systems might miss.
Random sampling proves particularly crucial for GenAI systems because they are susceptible to "silent degradation" - a phenomenon where outputs maintain good metric scores while becoming less effective in practice. For instance, a customer service AI might continue to achieve high ROUGE scores while providing less actionable information to users. Through random sampling, organizations can identify these cases where outputs achieve high metric scores but fail to meet actual user needs. This distinction requires monitoring not just metric values but the metrics themselves, creating a meta-level monitoring challenge unique to GenAI systems. Organizations implement continuous feedback loops that reassess metric effectiveness through careful analysis of user interactions.
This monitoring approach becomes even more vital when dealing with foundation models accessed through external APIs - a common architecture in GenAI systems. Unlike traditional ML systems where organizations train models from scratch on their specific data, GenAI systems often rely on external foundation models beyond their direct control. When providers update or deprecate these underlying models, it can impact system performance in subtle ways. For example, a model API upgrade might improve general performance but alter the model's reasoning ability, requiring adjustments to prompts or fine-tuning strategies.
Through this comprehensive monitoring approach, organizations can maintain robust oversight of their GenAI systems despite the unique challenges of external dependencies and potential silent degradations.
Tracing:
In traditional ML, tracing an incorrect prediction is straightforward – teams can directly examine the input features, model weights, and final prediction to understand what went wrong. There's typically no need to track intermediate steps since the prediction process is deterministic and follows a fixed pipeline. However, GenAI systems often involve multiple processing steps with intermediate outputs that must be traced. For example, a customer support AI might first classify the query type, then retrieve relevant documentation, and finally generate a response by combining this information. When the final output is problematic, organizations need to trace through each step to identify where the process went awry. This traceability becomes particularly challenging with AI agents, where the model dynamically decides which steps to take and which tools to use based on the context. In such cases, two identical queries might follow completely different execution paths, making it essential to maintain detailed traces of decision points, tool selections, and intermediate outputs for effective monitoring and debugging.
Post-deployment validation of GenAI outputs remains essential despite pre-deployment safeguards, with three primary types of guardrails: hallucination checks, ethical/bias controls, and brand tone verification. Traditional ML outputs are typically constrained to specific, pre-defined categories or numerical predictions, eliminating concerns about brand voice consistency or open-ended ethical implications.
Hallucination presents a unique challenge in GenAI systems, as they can produce convincing but inaccurate information. For instance, an AI handling insurance queries might confidently provide incorrect policy details, creating liability risks. Unlike traditional ML models, GenAI can generate inconsistent outputs for identical inputs, necessitating runtime guardrails beyond standard performance monitoring. These include analyzing semantic drift, checking for contradictions, validating claims, and employing multiple model consensus to identify potential hallucinations.
Ethical and bias controls involve regular auditing of response patterns across demographic groups, with specific fairness metrics under continuous monitoring. Organizations establish and maintain explicit ethical guidelines, ensuring transparency about system capabilities while documenting limitations and appropriate use cases. Regular reviews and updates of these principles occur based on real-world impact assessments.
Brand voice consistency requires continuous validation, implemented through LLM-based validators trained on company communications, encoded style guides, contextual appropriateness checks, and brand personality metrics. For example, if a company emphasizes warm, empathetic communication, guardrails would flag overly technical responses even if factually accurate.
When guardrails detect issues or in high-stakes scenarios, outputs are routed for human review through clearly established escalation pathways. The flowchart shows how GenAI systems require two critical runtime pathways: a "Pass" pathway for outputs that clear automated checks, and a "Review Needed" pathway that routes flagged outputs to human reviewers. This human-in-the-loop review process involves trained professionals who handle edge cases, provide rapid intervention for inappropriate content, and validate complex brand voice alignment. The system's effectiveness relies on tight integration between automated checks and human review, with continuous feedback loops refining both components.
Unlike traditional ML systems where model inputs follow rigid, predefined structures, GenAI systems often require carefully crafted prompts that serve as the interface between human intent and model capability. This fundamental difference emerges from GenAI's ability to process natural language instructions, making prompt engineering a crucial discipline that combines technical precision with domain expertise.
The flowchart illustrates how prompt engineering fits into a larger workflow, positioned after the "Prompt Chain & Model planning" phase. Teams must first determine whether a task can be effectively accomplished through prompt chains and plan how different prompts will work together. For instance, a customer support workflow might begin with a prompt that classifies the query type, followed by separate prompts for information retrieval and response generation. This structured approach to prompt chain design provides a framework for systematic prompt development and optimization.
The trade-off between prompt length and performance represents one of the most critical considerations in prompt engineering. Organizations must establish comprehensive testing frameworks that balance multiple competing factors. A minimal prompt might achieve faster response times but risk inconsistent outputs, while more detailed prompts can ensure reliability at the cost of increased processing overhead. Testing frameworks typically evaluate prompts across four key dimensions: reliability testing to verify consistent performance across diverse inputs and edge cases, cost analysis to measure and optimize token usage and processing time, quality assessment using both automated metrics and human evaluation to ensure outputs meet standards, and safety verification to confirm that prompts maintain model guardrails and prevent unsafe behavior. Through this systematic evaluation process, teams can quantify the impact of prompt length and complexity on both performance and operational costs.
Prompt versioning and performance tracking introduce a level of rigor absent in traditional ML feature engineering. Teams maintain prompt repositories where each version is tagged with performance metrics such as completion rate (percentage of successful responses), accuracy scores from automated evaluations, and user satisfaction ratings. These historical comparisons help teams understand how prompt modifications impact performance. For example, when a financial services chatbot shows declining accuracy in tax-related queries, teams can analyze how different prompt versions handled similar questions in the past, using this data to guide improvements.
The role of non-technical stakeholders in prompt engineering represents a significant departure from traditional ML practices. While feature engineering in traditional ML is primarily a technical exercise, effective prompt engineering requires cross-functional collaboration, relying heavily on non-technical stakeholders for crafting clear and reliable prompts. Legal experts help craft prompts that capture nuanced regulatory requirements, marketing teams ensure brand voice consistency, and subject matter experts validate technical accuracy. These stakeholders don't just provide input – they actively participate in prompt design and improve prompts with appropriate technical terminology, reasoning steps, or user persona details.
Unlike traditional ML systems where feedback primarily drives model retraining and feature engineering, GenAI feedback loops introduce unique complexities that fundamentally reshape how organizations learn from and improve their AI systems. The "Aggregate feedback for Workflow improvement" node in our flowchart illustrates this expanded feedback scope, showing how multiple streams - including direct user feedback, human-in-the-loop assessments, and monitoring data - must be synthesized to drive improvements across different system components.
The variable nature of GenAI outputs creates the first major departure from traditional ML feedback patterns. In traditional ML, when a model makes an incorrect prediction, the feedback is straightforward: the prediction was wrong, and the model needs to be adjusted to map that input to the correct output. However, GenAI systems might generate different but equally valid outputs for the same input, or produce outputs that are partially correct but need refinement in specific aspects like tone or detail level. This variability means organizations must develop sophisticated feedback taxonomies that capture not just correctness, but also aspects like reasoning quality, creativity, and contextual appropriateness.
The application of feedback in GenAI systems also differs fundamentally from traditional ML. When a traditional ML model receives feedback about poor performance, the solution typically involves retraining the model with additional data or adjusting feature engineering. In contrast, GenAI feedback might lead to multiple types of adjustments:
This multi-level adaptation process, where operational feedback can trigger revisions at any level of the system—from guardrails to metrics to workflow design—reflects the unique complexity of maintaining effective GenAI systems in production.
The fundamental differences between GenAI and traditional ML systems necessitate a complete reimagining of AI workflow design and implementation. While traditional ML focuses on specific predictive tasks with clear metrics, GenAI introduces complexities in evaluation, requiring balanced consideration of automated metrics, AI-based assessments, and human judgment. Organizations must master new disciplines like prompt engineering and implement sophisticated guardrails both before and after generation. Successful GenAI deployment demands robust monitoring systems that can detect subtle degradations and maintain traceability across multiple processing steps. The feedback loop becomes more intricate, potentially triggering adjustments across multiple system components—from prompt refinements to workflow redesigns. As GenAI continues to evolve, organizations that understand and adapt to these distinct characteristics will be better positioned to harness its potential while managing associated risks and challenges.
Dr. Rohit Aggarwal is a professor, AI researcher and practitioner. His research focuses on two complementary themes: how AI can augment human decision-making by improving learning, skill development, and productivity, and how humans can augment AI by embedding tacit knowledge and contextual insight to make systems more transparent, explainable, and aligned with human preferences. He has done AI consulting for many startups, SMEs and public listed companies. He has helped many companies integrate AI-based workflow automations across functional units, and developed conversational AI interfaces that enable users to interact with systems through natural dialogue.