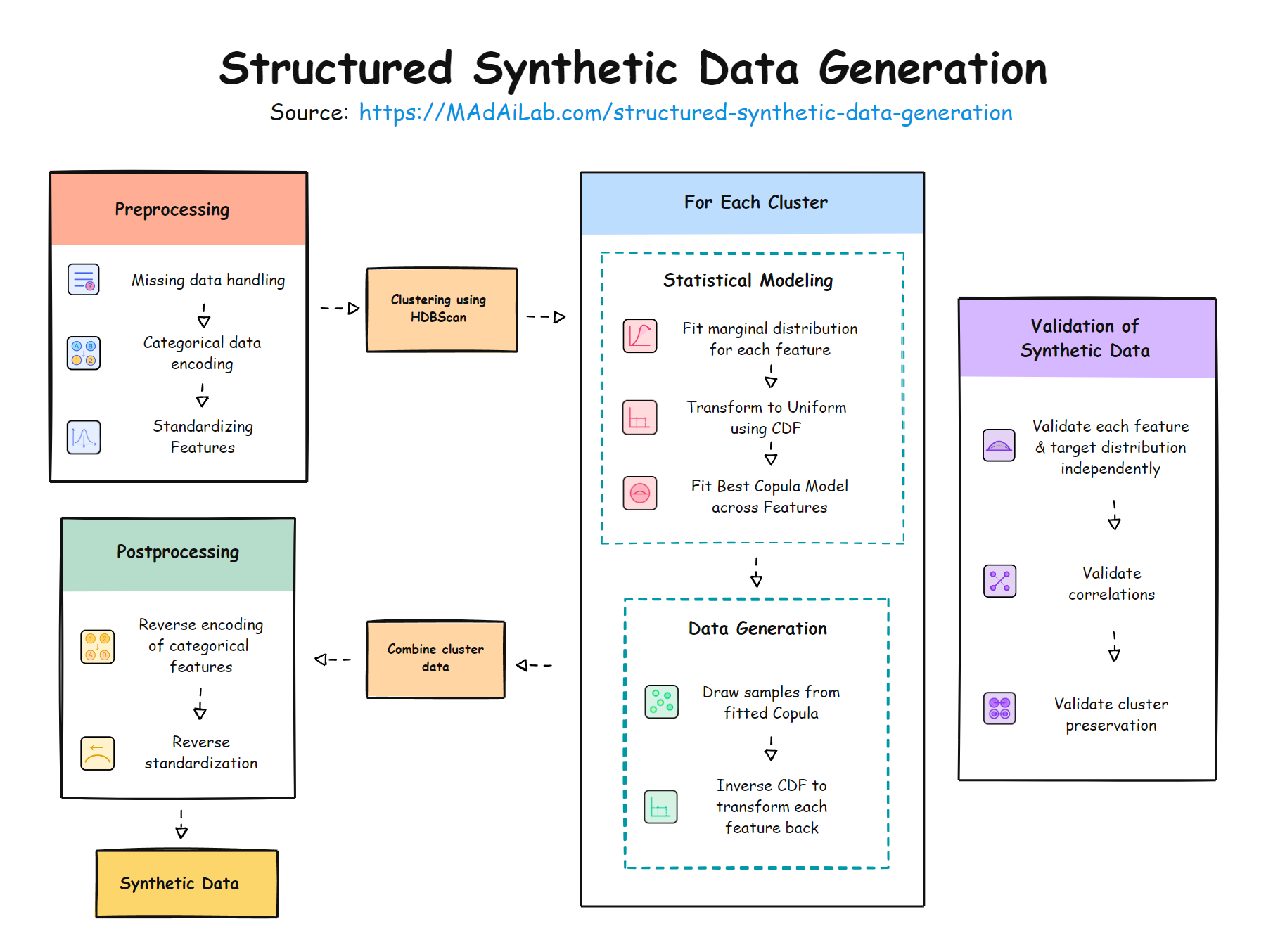
AI-coding tools are making significant inroads in the software development domain. These tools seem like magic when one first starts using them, as generating a fully functional application with just a few lines of instructions appears surreal. However, this initial excitement quickly subsides as code complexity increases.
In large codebases, AI tools often miss existing code, leading to duplication and inconsistencies. They also tend to forget prior instructions, causing repeated mistakes and forcing developers to reassert constraints. Debugging becomes a frustrating loop of false confidence—AI repeatedly claims to have identified issues, makes minor tweaks, but problems persist. This cycle of "Ah, I see the issue now..." followed by ineffective fixes rapidly grows tiresome. Over time, abandoned or broken code fragments—"ghost code"—accumulate, confusing the AI further and degrading generation quality.
Before digging deeper into why AI tools face these problems, it's important to first understand how AI coding tools work.
These tools use AI models such as Claude 3.7 Sonnet or ChatGPT-4o to generate code. A logical question to ask is what the role of the AI tool is if it doesn't generate code itself.
The tool's primary roles are:
Automated code improvement loops (Agentic): It performs agentic execution by running the modified code automatically using a terminal and observing any errors. If errors occur, the tool automatically creates a new prompt using those errors, adds relevant context and guidance, and sends it to the model. The model responds, the tool integrates the changes, and runs the code again. This process continues iteratively until either no errors remain, the maximum number of attempts is reached, or the user intervenes.
This agentic execution is both a blessing and a curse. When you provide minimal detailed instructions and allow the AI to operate based on its training, it often successfully replicates code without significant issues. However, as soon as you begin correcting it, adding logic, constraints, and other specific requirements, these tools increasingly struggle to identify the "right context" for your instructions. The key reason for this misidentified context is that as the sequence length (i.e., number of tokens) approaches approximately 60% of the context window (the maximum number of tokens the AI model can process), the model begins experiencing the 'lost in the middle' problem and tends to miss critical elements from the prompt.
The key challenge for these AI tools is to identify the relevant context without approaching the context window limit. Despite their best efforts, sequence length rapidly increases when these tools rely solely on code because code consumes significantly more tokens than text explanations for two main reasons:
Explanations in words requires far less tokens than code:
Explaining concepts in natural language requires far fewer tokens than implementing them in code. What might take just a few sentences to explain—such as "Create a login page with username and password options. Also integrate the option to sign in using Google, Facebook, and LinkedIn"—would translate to hundreds of lines of code when implemented with React packages, CSS, and various library imports.
Tokenization process:
The tokenization process used by underlying AI models is less efficient for code than for natural language. For instance,
| Original Text | tokens processed for input to GPT | number of characters | number of tokens generated |
| Loop over productTypes | loop, over, product, type, s | 22 | 5 |
for ( i = 0; i < count(productTypes); i++) { | for, (, i, =, 0, ;, i, <, count, (, product, type, s, ), ; , i, +, +, ), { | 44 | 20 |
Even accounting for the fact that the code has twice as many characters, it produces four times as many tokens as the equivalent natural language expression.
In summary, AI tools struggle to understand code context purely from the code itself because code often lacks the high-level meaning or intent behind it, making it difficult for AI to determine which parts are truly important. This is why prompt compression—reducing the amount of code or context in a prompt—remains such a significant challenge.
AI tools like Cursor and Windsurf try to help by using rules to guide the AI on what context to include. These rules can be set globally or just for a specific project, and they can change depending on the files or parts of the code you're working on. For example, Cursor lets you define rules that automatically include related files based on the code you're editing. Windsurf does something similar with its memory and context system.
While these tools don’t fully solve the problem—especially when it comes to deeper understanding like how pieces of code connect behind the scenes—they help the AI focus better.
Another promising aspect of modern AI tools is their use of markdown-based planning documents. Cline was one of the first to formalize this approach by introducing two distinct modes: Plan mode, which focuses on gathering requirements and outlining implementation steps in markdown, and Act mode, which uses those plans to guide actual code generation. Following Cline’s lead, tools like Cursor and Windsurf have also introduced similar planning-focused workflows in recent months.
In Plan mode, Cline can analyze relevant files, engage in dialogue to clarify objectives, and develop comprehensive implementation strategies. Cursor's Planner mode similarly supports creating detailed, context-aware plans, and its Agent mode can act on those plans autonomously, performing multi-step changes across a codebase. Windsurf brings a different strength with its Cascade system, which builds a semantic model of the project, helping the AI reason about dependencies across multiple files. These recent advances are pushing markdown planning from static outlines toward dynamic, interactive workflows that better support the complexity of modern software development.
However, these planning modes can still struggle when applied to large, modular codebases—particularly if the plans are kept too high-level or not continuously refined. While the initial documents often outline technologies, frameworks, and task breakdowns (e.g., to-do, in-progress, done), the depth of planning depends heavily on how the tools are configured and used. Without iterative refinement or deeper integration with the code structure, these documents may miss important implementation details—especially in systems where components span many interdependent files. That said, tools like Cline, Cursor, and Windsurf are actively evolving in this direction, with features that increasingly support context-aware, multi-file planning and documentation.
While AI tools can significantly benefit from markdown documents covering specifications explained in natural language, technical leads create these specifications separately from the code repos. Since specifications aren't typically stored in the code repo that AI tools can access, architects must manually provide all relevant context to effectively use AI assistance. This manual context-bridging is cumbersome and time-consuming, effectively creating a barrier that leads to minimal AI adoption during the architectural and design phases.
Having specifications in the code repository would greatly enhance AI's ability to decompose new requirements into specifications. In particular, it enables:
By contrast, if AI-generated specifications were stored directly in the code repository as markdown files:
The disconnect between specifications and implementation creates significant inefficiencies in the software development lifecycle. As highlighted earlier, while tools like Cline, Cursor, and Windsurf are evolving to support context-aware planning, the separation between specifications (created by technical leads) and code repositories (accessed by AI tools) creates a fundamental barrier to effective AI adoption in architectural and design phases.
Bringing specifications directly into the code repository—ideally as markdown files—solves this gap by making high-level system intent natively accessible to AI tools. This enables AI to participate meaningfully in system design by mapping dependencies across the codebase, maintaining consistency in structure and language, and identifying opportunities for code reuse. With the ability to cross-reference both the specifications and implementation, AI can generate more accurate scaffolding, propose system-level patterns, and ensure new additions align with existing architecture. The result is a more coherent, maintainable, and rapidly evolvable codebase—laying the groundwork for full-cycle AI involvement across system design, coding, and testing.
As illustrated in the image below, AI-augmented software development streamlines the traditional multi-role workflow into a highly integrated loop, compressing weeks of planning, coding, and testing into days.
In this model, AI doesn't merely assist at the code generation level—it participates actively across system design, development, and testing phases. By embedding specifications, code, and test logic into a shared context, AI can iterate through the entire software lifecycle far more fluidly and intelligently. Here's how this transformation takes place:
1. System Design Integration
AI tools start by asking clarifying questions, scaffold system designs, and generate specifications directly from high-level requirements. Unlike traditional setups where specs are abstracted from the implementation, here AI gains direct access to the evolving structure of the codebase. This tight feedback loop enhances architectural precision and accelerates design validation.
2. Continuous Contextual Coding
Once specifications are established, AI transitions smoothly into coding. Rather than treating code as isolated tasks, the AI draws from the broader system architecture and prior specifications to write aligned, reusable, and dependency-aware code. The ability to reference multi-file contexts significantly improves coherence across modules and helps avoid structural fragmentation.
3. Automated Testing & Error Recovery
AI doesn’t just generate tests—it iteratively runs and fixes them. When failures occur, it can trace them back through the system spec and implementation, identify the cause, and attempt auto-corrections. This reduces the back-and-forth cycle between developers and QA, tightening the feedback loop to near real-time.
Compression of Sprint Cycles
Where traditional development might require 2–3 weeks per sprint, AI-augmented workflows often converge in 3–5 days. This acceleration is not just a product of faster coding—it’s a reflection of reduced context switching, fewer handoffs, and automation of error resolution and testing.
The human's role is evolving—from writing every line of specification, code, and tests to guiding the AI, answering its questions, and correcting course when it goes off track.
New workflow:
AI: Writes ~90% of specifications, code, and tests
Human: Provides clarity, reviews output, fills in gaps, and occasionally writes the tricky parts
By saving specifications alongside code and allowing AI tools to operate across both spaces, this development paradigm reduces planning debt and eliminates many points of friction that slow down traditional software delivery. As AI-native tools continue evolving, the emphasis shifts from just writing code to managing a dynamic, context-rich development environment that continuously reasons about what’s being built—and why.
This new partnership fundamentally transforms how technical teams work. Rather than implementing every detail manually, teams now focus on higher-level concerns while leveraging AI to handle routine implementation tasks.
The AI handles most of the coding workload, generating specifications based on requirements, implementing standard patterns, writing routine tests, and handling boilerplate code. This frees the technical team to concentrate on what humans do best: providing domain expertise, making architectural decisions, reviewing for business alignment, and solving novel problems that the AI hasn't encountered in its training.
Technical teams become more like directors—guiding the AI with clear requirements, reviewing its output for quality and alignment with business goals, intervening when necessary to correct misunderstandings, and writing specialized components that require deep domain knowledge or innovative approaches.
This creates a multiplier effect where a single technical team with AI assistance can accomplish what previously required multiple teams of specialists, all while maintaining or even improving code quality and reducing technical debt.
Dr. Rohit Aggarwal is a professor, AI researcher and practitioner. His research focuses on two complementary themes: how AI can augment human decision-making by improving learning, skill development, and productivity, and how humans can augment AI by embedding tacit knowledge and contextual insight to make systems more transparent, explainable, and aligned with human preferences. He has done AI consulting for many startups, SMEs and public listed companies. He has helped many companies integrate AI-based workflow automations across functional units, and developed conversational AI interfaces that enable users to interact with systems through natural dialogue.