Simple LLM conversions of n8n workflows fail silently due to recursion bugs, complex authentication issues, and flawed architectures. We solved this by building a resilient 8-guide "mega-prompt" framework that forces the LLM to analyze workflow complexity, choose the correct API paradigm (Functional vs. Graph), and engineer environment-aware authentication, resulting in a production-ready application.
No-code platforms like n8n have revolutionized automation, enabling users to visually build complex workflows. Developers, however, often encounter a ceiling where they require more granular control, scalability, and cost-efficiency than a visual builder can offer.
The logical next step is to migrate these visual workflows to a powerful, code-native framework, such as LangGraph. The "obvious" solution is to use a Large Language Model (LLM) to perform the conversion. However, a simple, direct translation often produces code that is brittle and fails under real-world conditions.
This article is not just a tutorial. It is a case study on how to build a robust and resilient conversion framework. We will walk through the critical failures we discovered in a simple conversion—including recursion errors and authentication dead-ends—and detail the advanced, 8-guide "mega-prompt" system we engineered to solve them
To pressure-test our conversion framework, we needed a complex, real-world scenario. We found a perfect example inspired by a Gumloop tutorial on YouTube: automating outbound sales.
TUTORIAL: Automating Outbound Sales with AI
Source: https://www.youtube.com/watch?v=Jxacz1_YHuo
The Goal: Convert a simple list of company URLs into personalized outreach emails.
This workflow is an ideal test case because it requires:
This combination of features is a perfect recipe for the exact kind of subtle bugs that plague simple LLM-generated code. This article is intended for developers, AI engineers, and technical managers who want to build reliable, production-grade applications from visual concepts.
This project began as a challenge from Professor Rohit Aggarwal to explore the systematic conversion of visual workflows into production-grade code.
The professor provided the foundational challenge and a 3-step "base" prompt chain from prior work with students. This framework could translate n8n JSON into a Project Requirements Document (PRD), handle custom code, and generate an initial LangGraph implementation.
My role was to apply this base framework to the "Outbound Sales" test case. In doing so, I quickly identified several critical, real-world failures: the generated code was brittle, falling into recursion loops (GraphRecursionError), and failing on Google authentication in any server environment (headless, WSL, or Docker). Furthermore, the framework's architecture was inflexible, always defaulting to a complex design, even when a simpler one would have been sufficient.
Following high-level conceptual guidance from the Professor to adopt a modular architecture (adhering to DRY principles), I architected and authored the solutions. My primary contributions were:
The Professor provided invaluable conceptual guidance and regular feedback throughout this process.
When we applied the base framework to the "Outbound Sales" workflow, we encountered three critical failures immediately. These are the silent problems that turn a "90% complete" AI-generated script into a multi-day debugging session.
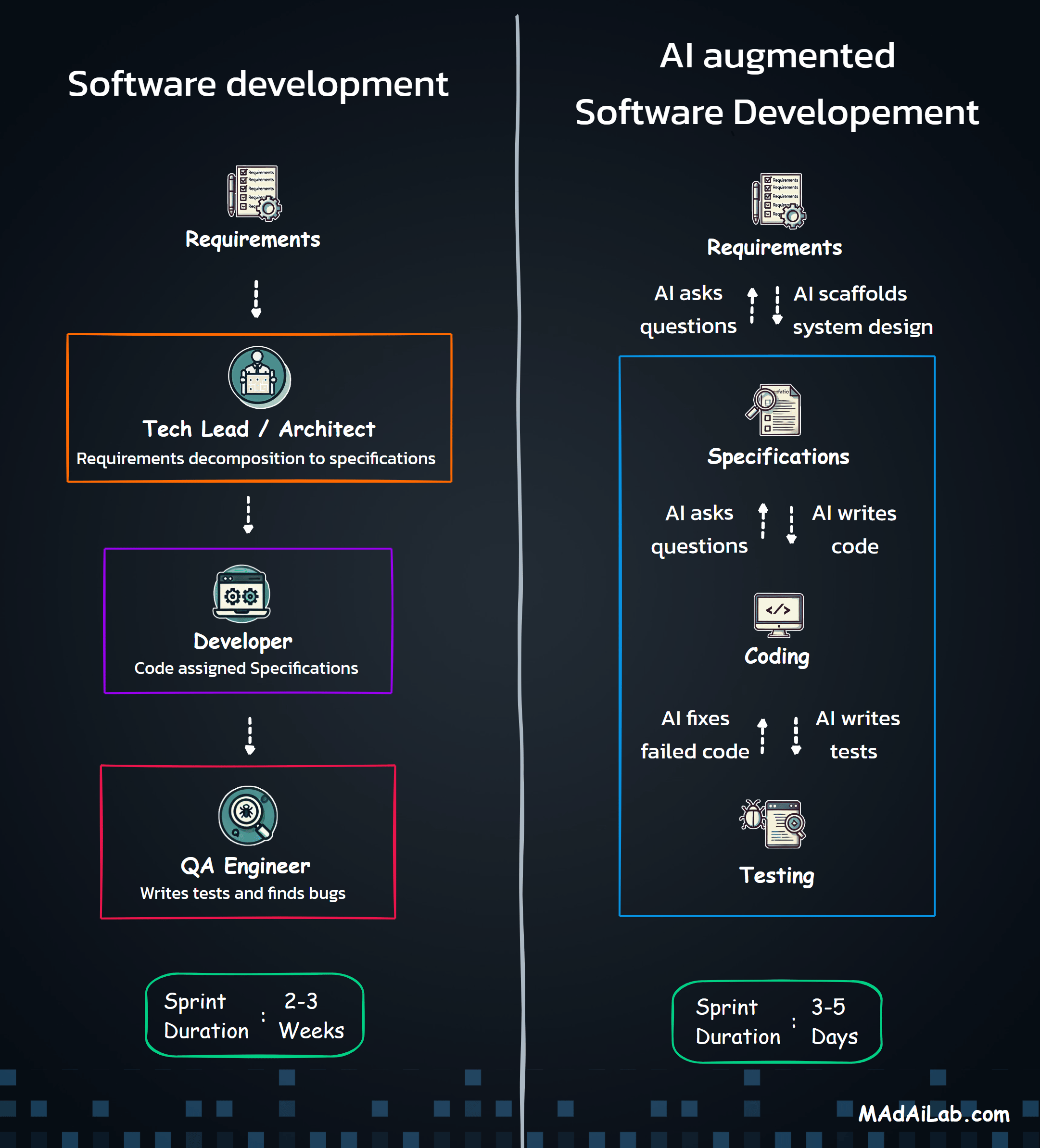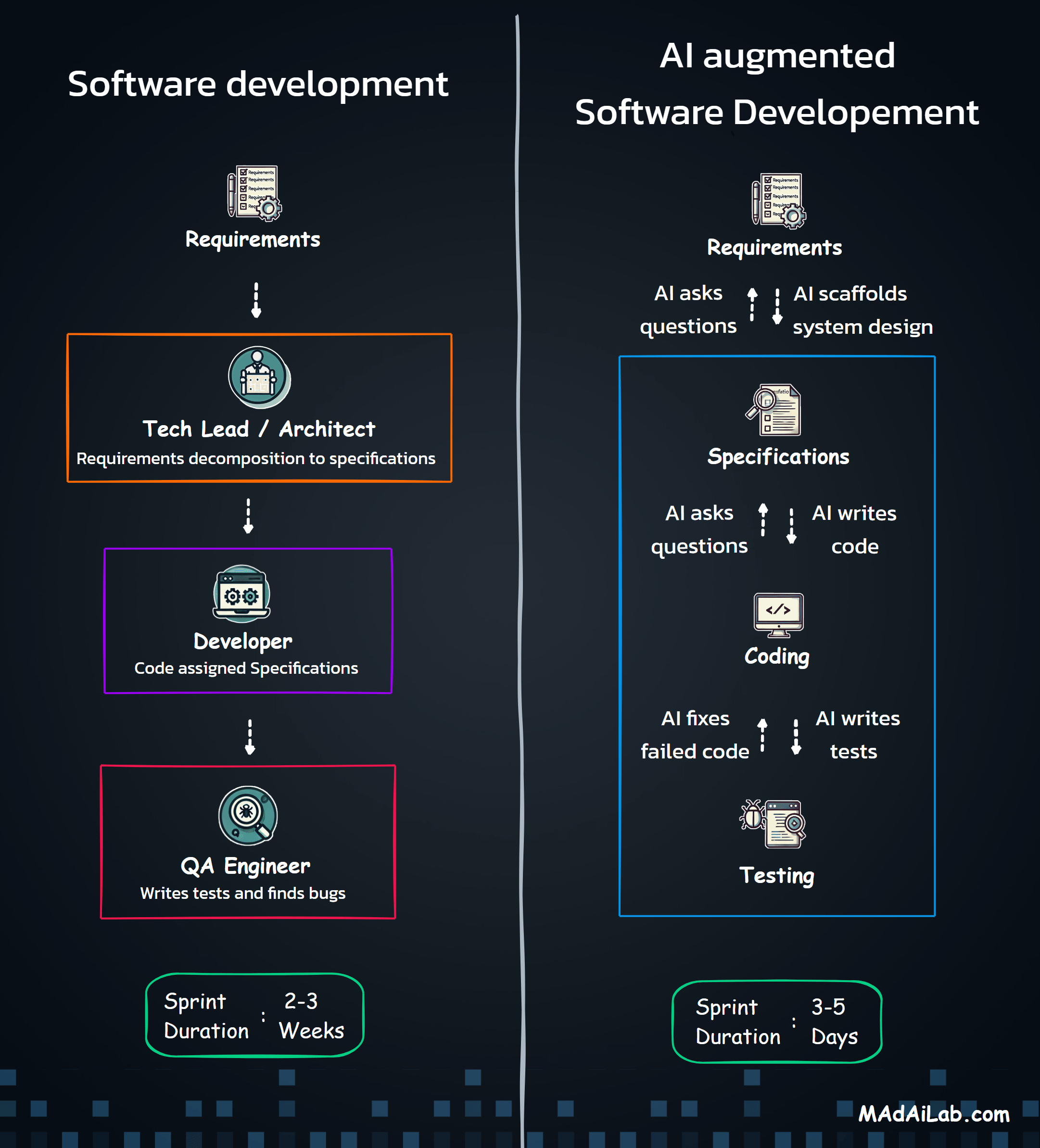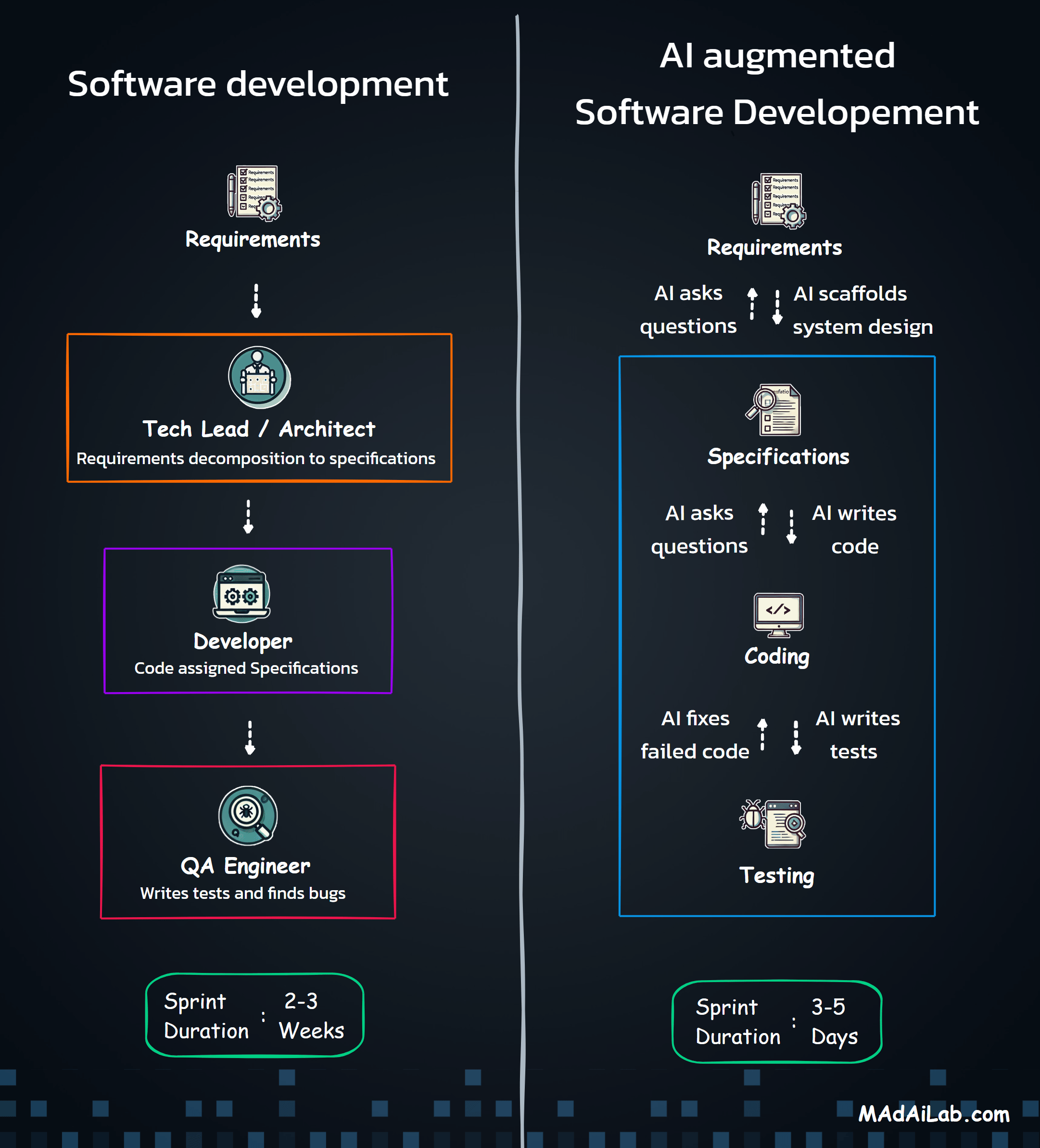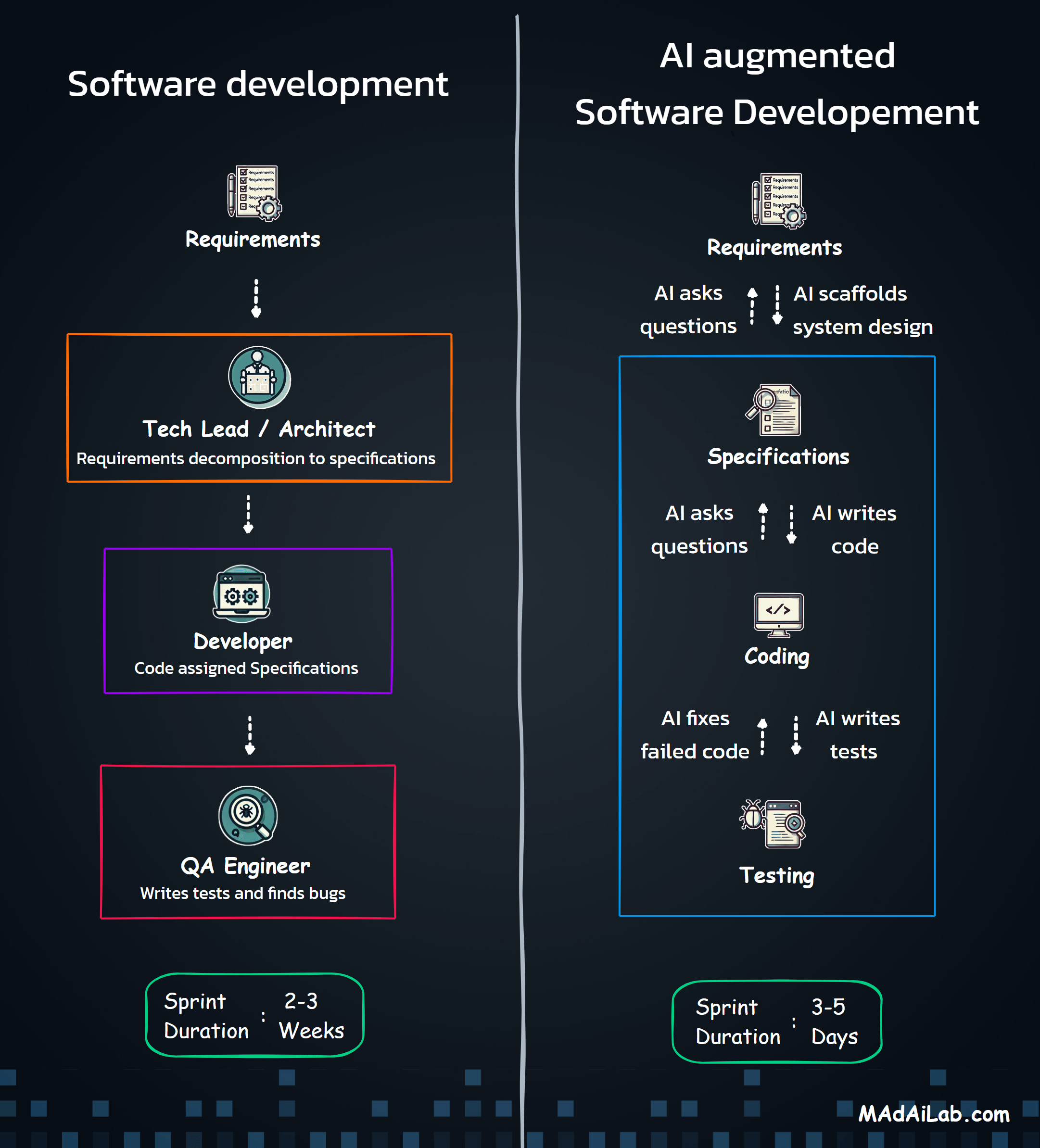
The base framework had a major architectural flaw: it always defaulted to a LangGraph Graph API, forcing even simple, linear workflows into a complex, stateful, recursive "controller node" pattern. This was inflexible, overly complicated, and the root cause of our next error. We needed a smarter framework that could choose the right tool for the job—a simple Functional API for most tasks and the Graph API only for complex workflows that truly required it.
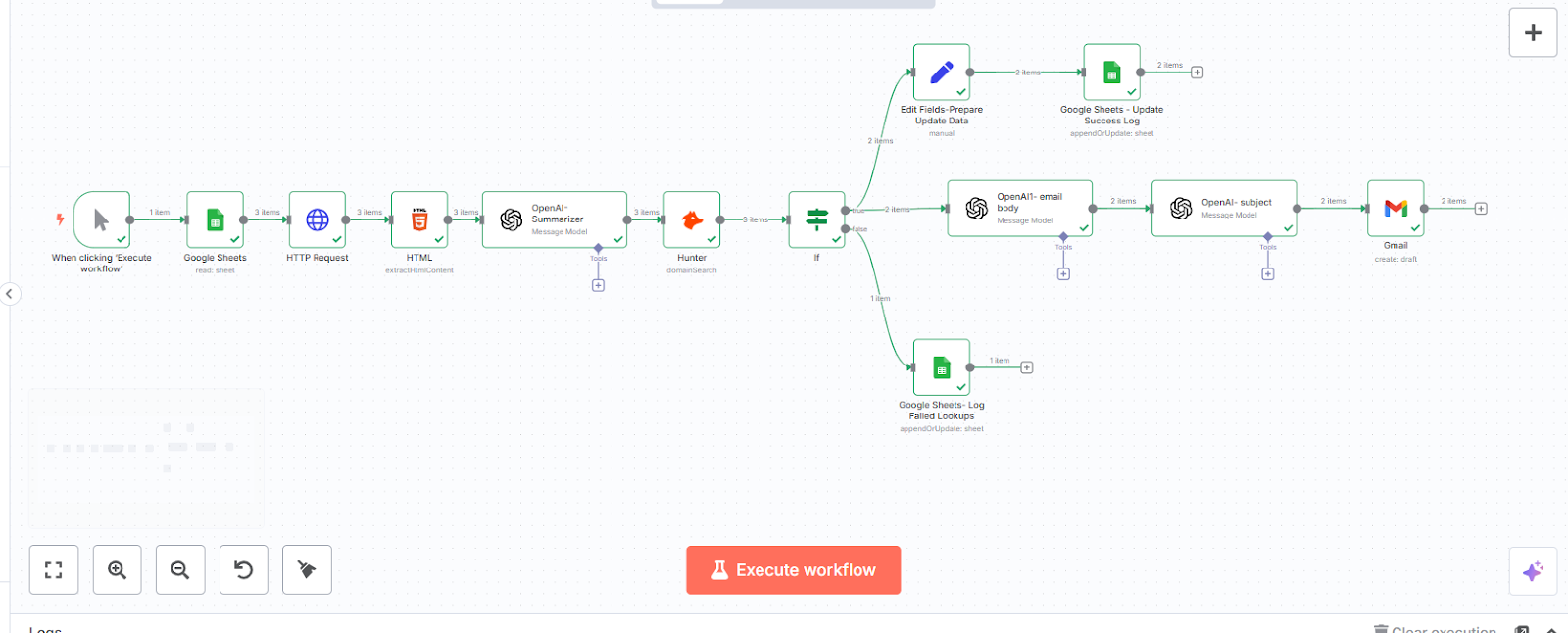
A direct result of the flawed architecture, the default "controller node" logic was buggy. When processing a list of companies, it would hit LangGraph's built-in recursion limit and crash.
Using LangSmith to trace the execution, we found the bug: if the last company in the list failed a step (e.g., no email was found), the graph's state was never cleared. It would loop back to the controller node and endlessly re-process the same failed item, creating an infinite loop.
Buggy Flow Screenshot from LangSmith
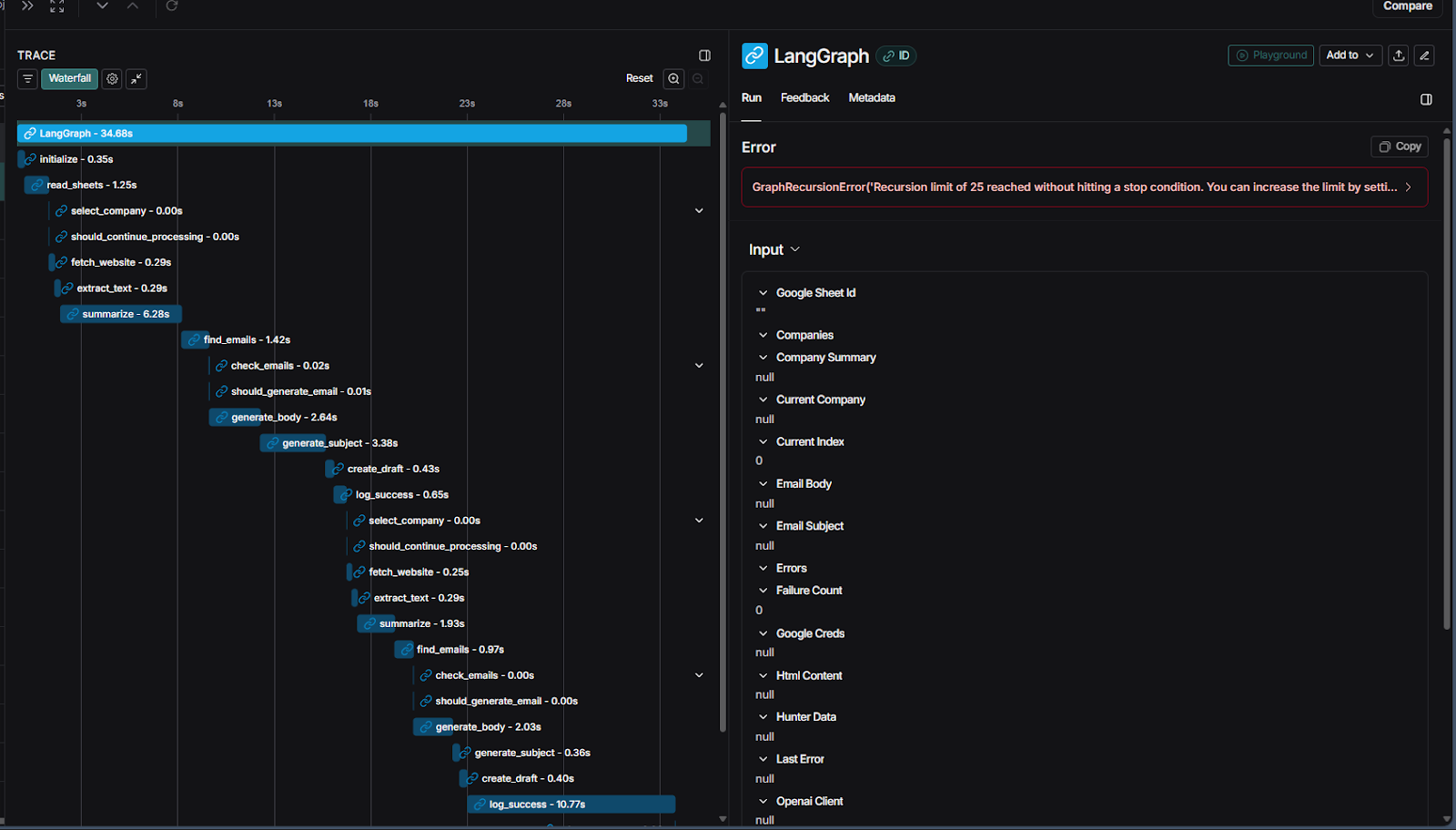
See the Fixed Flow on LangSmith
The generated code for Google Authentication used flow.run_local_server(). This method works perfectly on a local machine by automatically opening a browser window for user consent. However, it fails instantly and silently in any headless environment, including servers, Docker containers, or WSL.
Worse, there is a common pitfall where developers use "Web application" credentials from the Google Cloud Console instead of "Desktop app" credentials. This leads to an impossible-to-debug redirect_uri error, completely halting the project.
To overcome these issues, we designed a resilient, three-step prompt system. This architecture breaks down the problem into multiple prompts. Step 3 involves a single "Main Prompt" (acting as the orchestrator) and eight modular "Guides" (representing different "skills"). The Main Prompt is programmed to review all eight guides thoroughly before generating any code. This approach guarantees that the output is robust, aware of its environment, and architecturally sound.
This robust framework allows us to systematically convert the n8n workflow. The first three steps generate the application, and the fourth step configures it to run.
First, we export the n8n workflow as a JSON file. We then use the ProductionRequirements.md to convert that JSON into a detailed, human-readable Project Requirements Document (PRD). This separates the platform's features from the specific business logic.
Link to the file: ProductionRequirements.md
If the n8n workflow uses custom "Function" or "Code" nodes, we use the CustomLogic.md to analyze them and generate detailed requirements, ensuring no unique logic is lost.
Link to the file: CustomLogic.md
This is the core step. We feed the n8n JSON (from Step 1) and any custom node requirements (from Step 2) into our MainOrchestorPrompt.md. The LLM reads our 8 Guides and generates a complete, robust, and environment-aware Python application.
The Main Orchestrator Prompt
This is the core prompt that orchestrates the entire conversion. It explicitly forces the LLM to read the guides, analyze the workflow, choose a paradigm, and cross-reference its own work against the guides.
Link to the file: MainOrchestorPrompt.md
# n8n to LangGraph Conversion Prompt
## Task Overview
Convert the provided n8n JSON workflow into a LangGraph implementation. **All implementations must use LangGraph** - analyze workflow complexity to determine whether to use Functional API (`@entrypoint`) or Graph API (`StateGraph`). Maintain original workflow logic, data flow, and functionality.
**CRITICAL FIRST STEP: Before analyzing the workflow, you MUST read ALL guide files in the `guides/` directory to understand implementation patterns, authentication requirements, API integration approaches, project structure standards, and testing methodologies.**
## Execution Process (Follow These Steps)
### Phase 1: Guide Review (MANDATORY FIRST STEP)
1. Read ALL guide files in the `guides/` directory:
- `guides/paradigm-selection.md`
- `guides/functional-api-implementation.md`
- `guides/graph-api-implementation.md`
- `guides/authentication-setup.md`
- `guides/api-integration.md`
- `guides/project-structure.md`
- `guides/testing-and-troubleshooting.md`
- `guides/output-requirements.md`
2. Understand paradigm selection criteria, implementation patterns, authentication requirements, API integration patterns, project structure standards, and testing approaches from the guides
### Phase 2: Workflow Analysis
3.Read and analyze the n8n JSON workflow
4. Scan n8n JSON for custom node placeholders pointing to `/req-for-custom-nodes/<node-name>.md`
5. Read all referenced custom node requirement files completely
6. Analyze workflow complexity using decision framework from guides
### Phase 3: Implementation Planning
7. Select implementation paradigm (default to Functional API with `@entrypoint` unless complexity requires Graph API with `StateGraph`)
8. Select execution pattern (default to Synchronous for simplicity unless async concurrency truly needed)
9. Plan custom node translations to Python functions appropriate for chosen paradigm and execution pattern
### Phase 4: Implementation
10. Create complete LangGraph implementation using proper decorators (`@entrypoint`/`@task` or `StateGraph`), parameters, and patterns from guides
11. Ensure sync/async consistency - if entrypoint is synchronous, all tasks must be synchronous with synchronous method calls; if entrypoint is async, all tasks must be async with await statements
12. Document all conversions with custom node traceability and documentation references
### Phase 5: Final Review
13. **MANDATORY FINAL GUIDE REVIEW** - Cross-reference implementation against all guides:
- Paradigm selection guide
- Implementation guide for chosen paradigm
- Authentication setup guide
- API integration guide
- Project structure guide
- Testing and troubleshooting guide
- Output requirements guide
14. **CRITICAL**: Verify LangGraph decorators present and sync/async pattern consistent - NEVER plain Python without `@entrypoint` or `StateGraph`, NEVER mix sync entrypoint with async tasksThese guides are the core "brain" of our framework. They provide the LLM with the expert knowledge required to build production-ready code.
paradigm-selection.md
This guide solves Failure 1. It forces the LLM to analyze the workflow's complexity and justify its choice between the simple Functional API or the more complex Graph API, breaking the inflexible "controller node" default.
Link to the file: paradigm-selection.md
The generated code is runnable but requires configuration. This guide ensures a user can set it up correctly.
1. Create the .env file: Create a file named .env in the project's root directory. The LLM will have provided a .env.template (as per output-requirements.md) to use as a guide.
2. Obtain API Keys :
The specific API keys you need will depend on the services used in your n8n workflow. The LLM will list the required environment variables in the .env.template it generates.
For our "Automated Outbound Sales" use case, the following keys were required. You can follow this as an example for your own keys:
3. Google Authentication Setup (The Right Way):
While this framework successfully handles services like Google and OpenAI, we identified a limitation we call the "Generation Gap." If an n8n workflow uses a less common service, a proprietary internal tool, or a rapidly updated library, the LLM may not have sufficient training data.
In these cases, the generated code is likely to be generic, outdated, or incorrect. It highlights that the more niche the tool, the more developer expertise is required to bridge the gap and manually refine the generated code. This is a challenge that could potentially be addressed by a solution like the Model Context Protocol, but this is a topic for later discussion.
This exploration evolved from a simple conversion exercise into a comprehensive examination of production readiness. The journey from a visual n8n workflow to a functional LangGraph application is not a single-shot conversion; it is a process of engineering for resilience.
While LLMs are remarkably powerful code generators, our role as developers is to act as architects and quality engineers. We must guide them, anticipate real-world complexities, and engineer robust frameworks that solve for the inevitable edge cases. The leap from a simple prompt to a comprehensive, 8-guide system is the true "pro-code" leap, transforming a brittle script into a scalable application.
I would like to extend a sincere thank you to Professor Rohit Aggarwal for providing the opportunity, the foundational framework, and invaluable guidance for this project. Thanks also to the students whose initial work provided the starting point, and to the creator of the original Gumloop YouTube video for an inspiring and practical use case.
Hitesh Balegar is a graduate student in Computer Science (AI Track) at the University of Utah, specializing in the design of production-grade AI systems and intelligent agents. He is particularly interested in how effective human-AI collaboration can be utilized to build sophisticated autonomous agents using frameworks such as LangGraph and advanced RAG pipelines. His work spans multimodal LLMs, voice-automation systems, and large-scale data workflows deployed across enterprise environments. Before attending graduate school, he led engineering initiatives at CVS Health and Zmanda, shipping high-impact systems used by thousands of users and spanning over 470 commercial locations.
Dr. Rohit Aggarwal is a professor, AI researcher and practitioner. His research focuses on two complementary themes: how AI can augment human decision-making by improving learning, skill development, and productivity, and how humans can augment AI by embedding tacit knowledge and contextual insight to make systems more transparent, explainable, and aligned with human preferences. He has done AI consulting for many startups, SMEs and public listed companies. He has helped many companies integrate AI-based workflow automations across functional units, and developed conversational AI interfaces that enable users to interact with systems through natural dialogue.