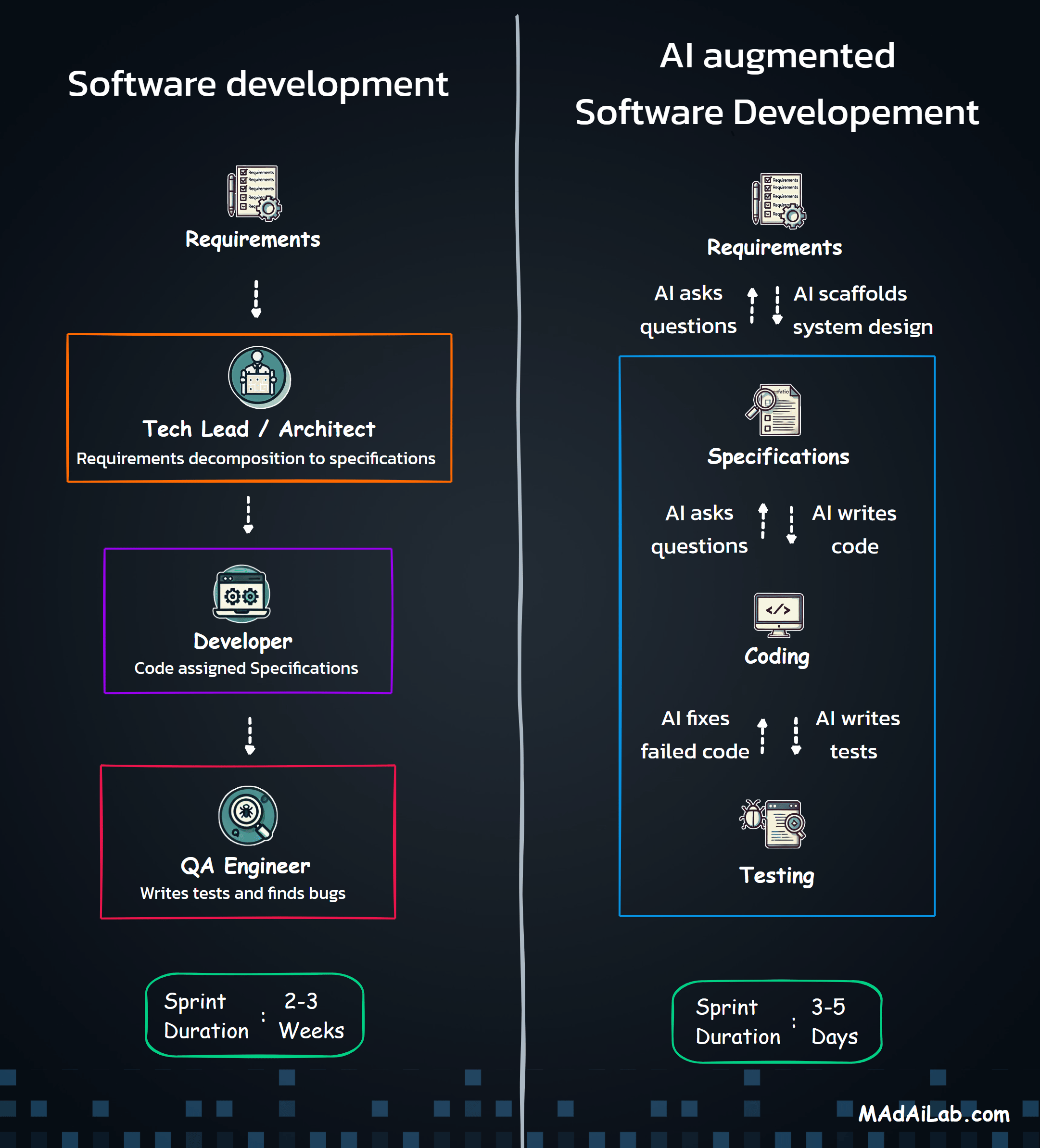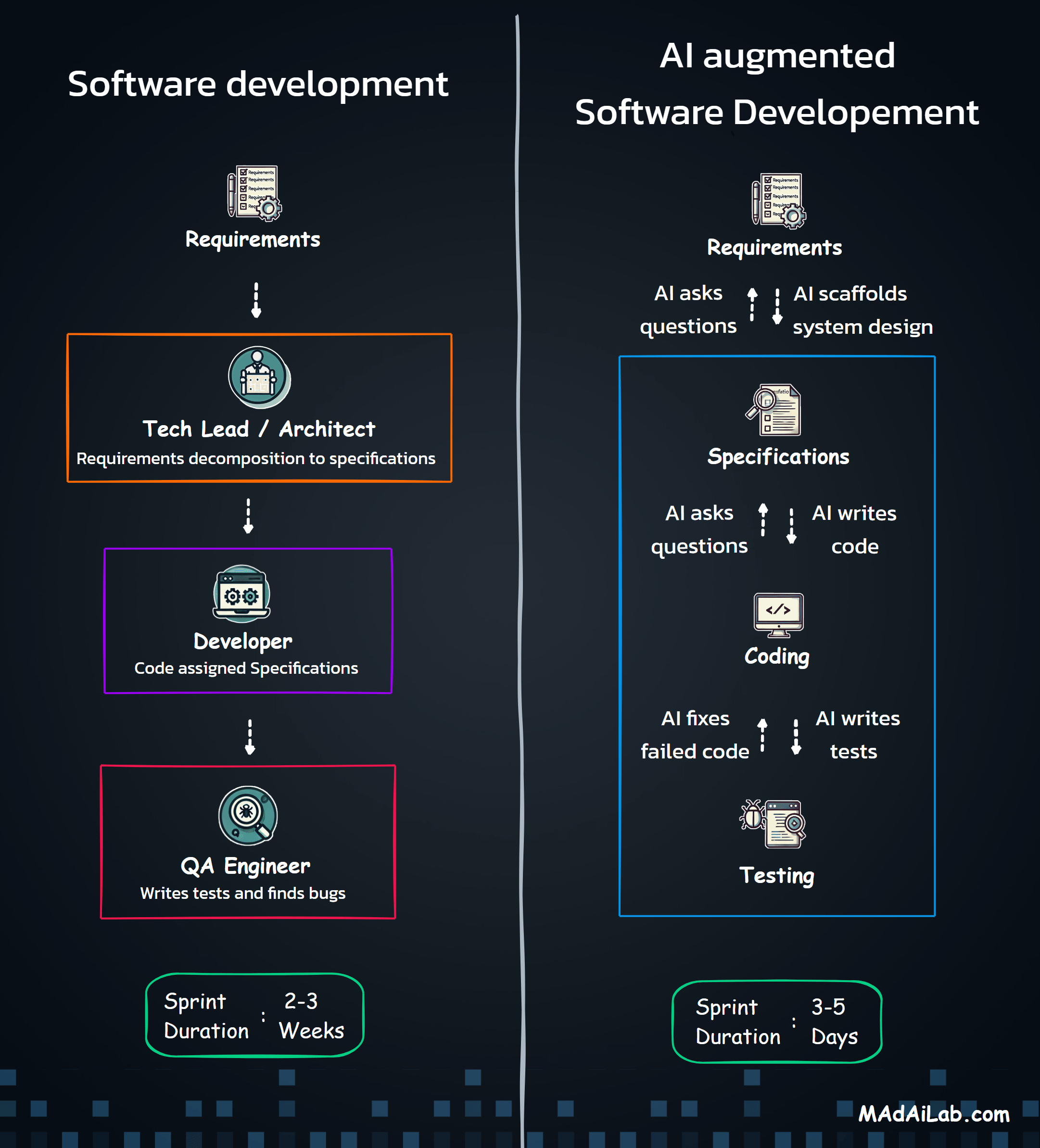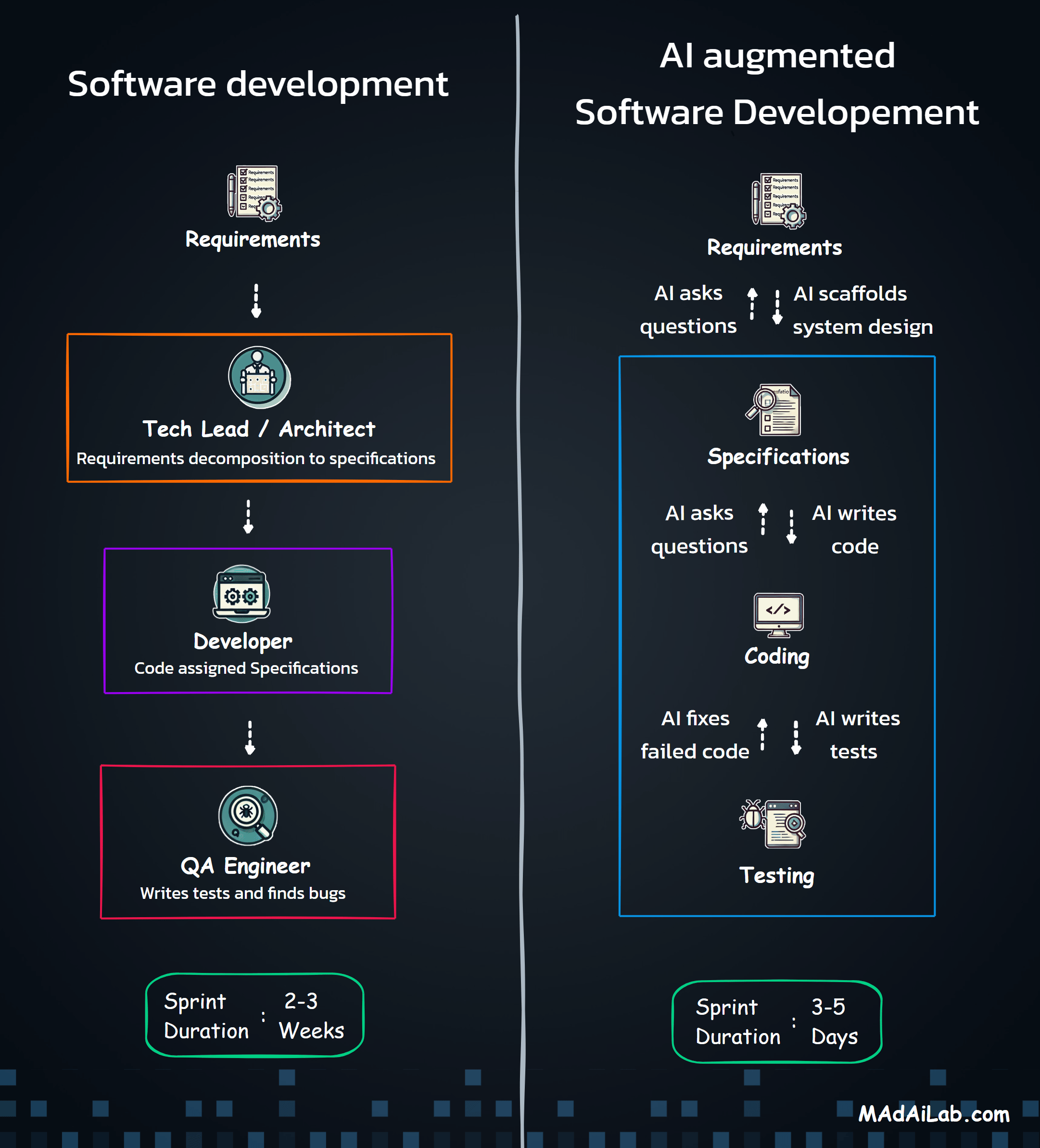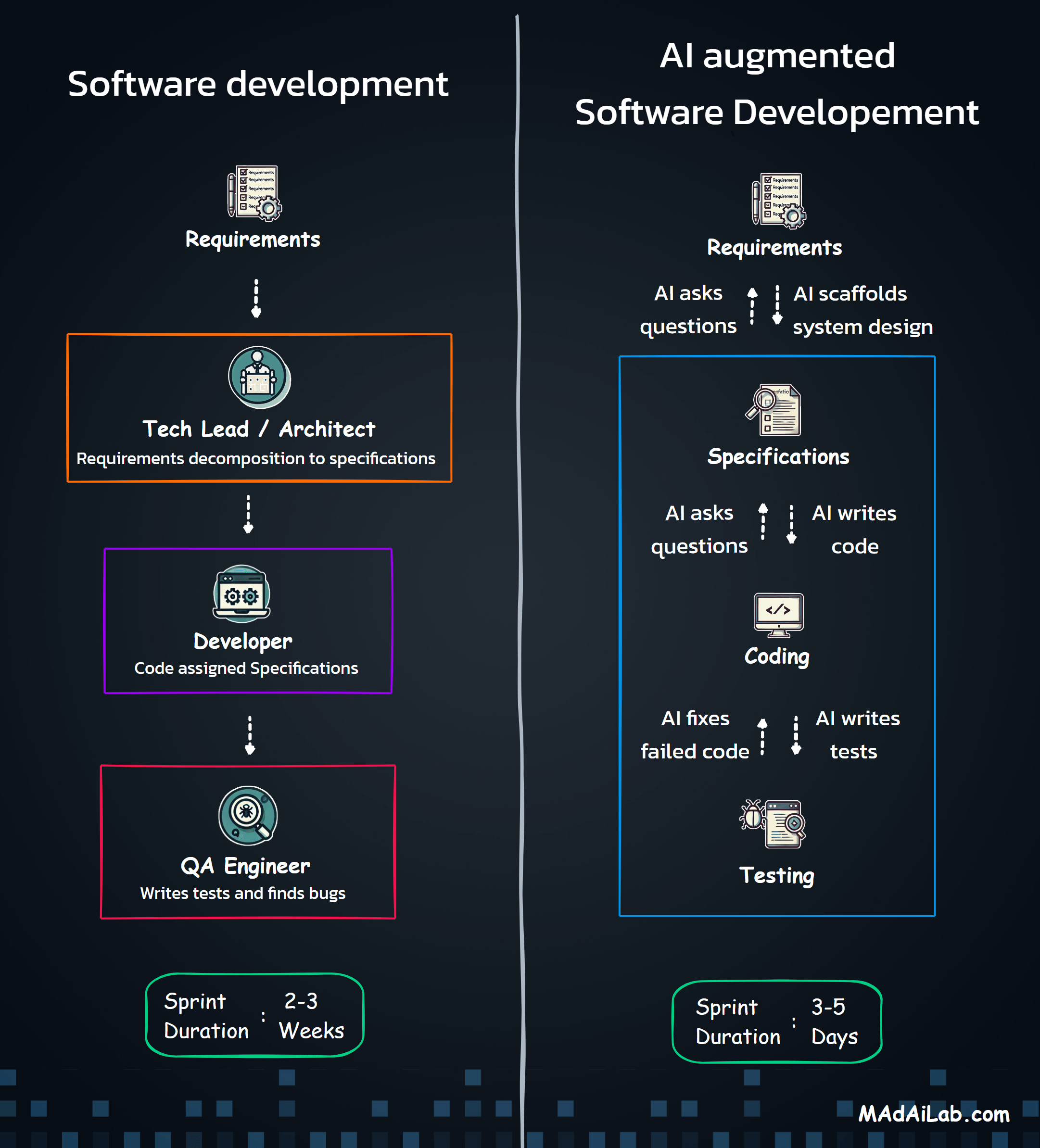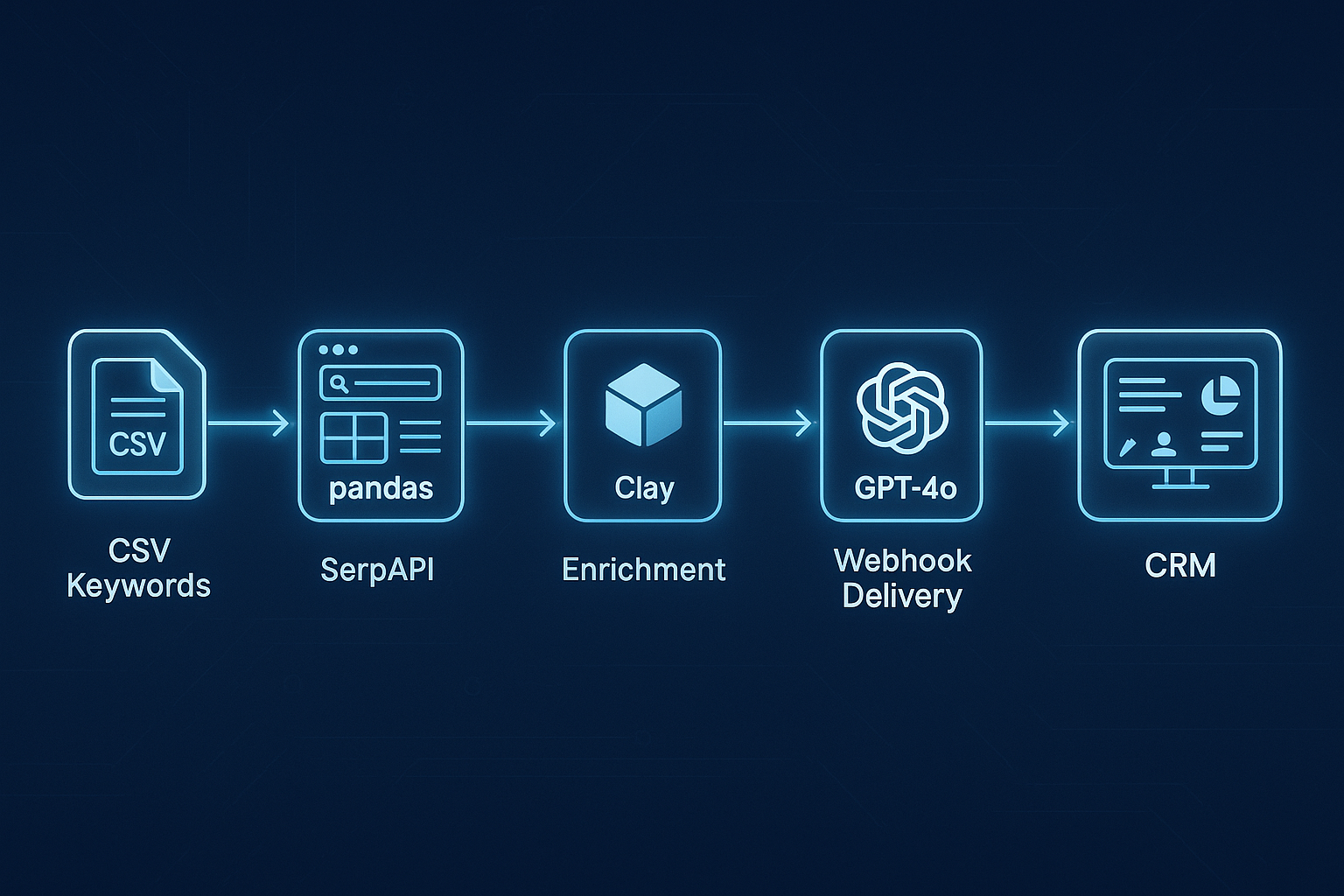
Built a GPT-4o + Clay + SerpAPI pipeline that automates end-to-end lead generation and enrichment — transforming a 2-hour manual task into a 3-minute automated workflow.
Mentored by Prof. Rohit Aggarwal under the MSJ 501(c)(3) initiative, this project demonstrates how structured AI automation can bridge academic learning and real-world business impact
What if a 2-hour manual task in sales could be reduced to 3 minutes — with over 90% accuracy and zero human input?
Lead generation is one of the most repetitive and error-prone tasks in modern business operations. Sales and marketing teams spend countless hours finding, verifying, and enriching potential leads — a process that’s often slow, inconsistent, and limited by human bandwidth.
This project set out to solve that problem by creating a fully automated AI-driven Lead Generation and Enrichment Pipeline capable of discovering, validating, and personalizing leads at scale. The workflow integrates SerpAPI, pandas, Clay, and GPT-4o, transforming raw search inputs into enriched, sales-ready profiles — all without manual intervention.
The result: a modular, low-code system that delivers 90%+ enrichment accuracy, real-time webhook delivery, and scalable personalization — a true example of how Generative AI can operationalize business intelligence.
Traditional lead research involves visiting multiple sites, manually collecting LinkedIn or company data, verifying emails, and adding details to CRMs.
Even with automation tools, data fragmentation and inconsistencies persist.
Our goal was clear:
Design a modular, API-driven pipeline that can autonomously collect, clean, enrich, and personalize leads at scale — using Generative AI as the connective tissue.
To achieve this, the system needed to:
1. Collect leads via targeted Google SERP extraction.
2. Clean and normalize the results into structured formats.
3. Enrich each profile with verified emails, company data, and funding information.
4. Personalize outreach messages using GPT.
5. Deliver outputs seamlessly via webhooks into Clay for real-time visibility.
The pipeline was designed as a sequence of independent yet interlinked modules:
1️⃣ Search Term Definition — Why CSV?
Using a CSV file made the pipeline modular and reproducible. Each row defines a persona + location combination (e.g., “AI founder San Francisco”), allowing batch experiments or easy scaling later.
2️⃣ SERP Collection — Why SerpAPI?
Instead of writing a custom scraper for Google or Bing — which would break often — SerpAPI provides structured JSON access to search results with stable formatting and metadata. This made the system resilient to HTML changes and allowed faster iteration.
3️⃣ Data Processing — Why Pandas?
Pandas handles cleaning, deduplication, and schema alignment in one place. It also enables quick CSV-to-JSON transformations that match the format Clay’s webhook expects.
4️⃣ Clay Enrichment — Why Clay?
Clay acts as a meta-enrichment engine: it connects to multiple providers (Hunter, Dropcontact, Crunchbase, etc.) through one unified API. Instead of writing separate connectors for each service, Clay orchestrates everything — person, company, email, and funding enrichment — saving both time and cost.
5️⃣ AI Personalization — Why GPT-4.1-mini?
After data enrichment, GPT-4.1-mini converts structured info into context-aware outreach notes. It’s lightweight, fast, and good enough for short contextual writing — ideal for a real-time pipeline.
6️⃣ Webhook Integration — Why Webhooks Instead of CSV Uploads?
Direct JSON delivery to Clay removes manual steps and allows real-time debugging. This also makes the pipeline future-proof — the same webhook endpoint can send data to any CRM or automation tool.
Building the system revealed multiple integration challenges that demanded careful debugging, creative pivots, and iterative experimentation.
1️⃣ Markdown-First Extraction — Why it worked:
Early HTML parsing attempts failed due to inconsistent markup and dynamic content across sites. Converting HTML → Markdown standardized structure and eliminated parsing errors. This elegant middle ground between raw scraping and full browser automation made GPT parsing stable and domain-agnostic.
Impact: Parsing failures dropped to zero, and the pipeline became both leaner and easier to extend.
2️⃣ Webhook Automation & Schema Validation — Why it mattered:
Initially, Clay uploads were manual CSV imports prone to mismatches. Automating delivery through webhooks created a real-time data stream between scripts and Clay. To ensure reliability, I added schema validation before every webhook call—preventing silent errors from minor field mismatches.
Impact: Debugging became instantaneous, API credits were preserved, and the workflow scaled automatically without human intervention.
3️⃣ Sequential Waterfall Logic — Why it was efficient:
Calling multiple enrichment providers in parallel seemed faster but wasted credits when one succeeded early. A waterfall sequence (stop after first success) optimized cost and accuracy while reducing redundant API calls.
Impact: The pipeline balanced speed and cost with intelligent sequencing logic.
4️⃣ Minimal Viable Input — Why it was a turning point:
Instead of fetching entire company profiles, the system now starts with a single LinkedIn URL. Clay automatically cascades person, company, and contact enrichment from that seed.
Impact: Processing became faster and cheaper—shifting from brute-force enrichment to context-aware automation.
5️⃣ Reflection & Mock Mode — Why it improved iteration:
Introducing a mock mode allowed testing logic without burning API credits, while a reflection loop enabled the system to self-check outputs and retry intelligently.
Impact: These two tools made debugging safer, more affordable, and more adaptive under real-world data variability.
6️⃣ GPT-4o Vision Integration — Why it was transformative:
When the original UI-TARS model became unavailable, switching to GPT-4o Vision unlocked multimodal reasoning directly from screenshots.
Impact: This consolidated perception and logic into one engine, simplified architecture, and expanded automation possibilities far beyond the original scope.
Once fully automated, the pipeline transformed a 2-hour manual process into a 3-minute AI-orchestrated workflow — a 40× productivity gain per batch of leads.
Quantitative Outcomes:
Qualitative Validation:
Performance was benchmarked and reviewed under the guidance of Prof. Rohit Aggarwal, who provided iterative feedback on pipeline reliability, schema validation, and data-flow transparency. The combination of deterministic logic (pandas, validation scripts) and probabilistic reasoning (GPT-4o) proved to be the key to both scalability and trust.
In business terms, the system frees up ~10 hours per week per analyst, improves consistency across outreach data, and scales instantly as new personas or markets are added — bringing AI automation from theory to tangible ROI.
This project reinforced a critical insight: AI alone isn’t enough — structured integration makes it powerful.
Combining deterministic modules (pandas, schema validation) with probabilistic reasoning (GPT) created a hybrid system that’s robust, cost-efficient, and transparent.
Next steps:
• Add a dashboard for error analytics.
• Expand enrichment to multiple CRMs.
• Integrate real-time alerts for schema drifts.
• Extend markdown-first approach to other sources.
This project was completed under the mentorship of Professor Rohit Aggarwal through Mentor Students & Juniors, Inc. non-profit that connects academic learning with real-world application. Professor Aggarwal provided guidance in project design, tool selection, and technical direction, along with regular feedback on implementation and presentation. His structured support helped ensure the project stayed aligned with both educational and practical objectives.
My name is Murtaza Shafiq. I’m currently pursuing an MS in Business Analytics & Information Management at Purdue University while contributing as a Data Science Consultant at AgReliant Genetics. There, I’m focused on optimizing supply chain operations — building stochastic models and Tableau dashboards to support executive decision-making. My background spans roles in SaaS, analytics consulting, and client-facing strategy. At EZO, I helped close Fortune 100 clients by aligning technical solutions with business needs. At AverLynx, I led cross-functional teams delivering data science projects — from A/B testing and forecasting to customer segmentation. I enjoy solving real-world problems through data and bring a mix of technical expertise (Python, SQL, Tableau, Power BI) and consultative experience to every project. I’m especially drawn to roles where data meets decision-making — where insights translate directly into impact.
Dr. Rohit Aggarwal is a professor, AI researcher and practitioner. His research focuses on two complementary themes: how AI can augment human decision-making by improving learning, skill development, and productivity, and how humans can augment AI by embedding tacit knowledge and contextual insight to make systems more transparent, explainable, and aligned with human preferences. He has done AI consulting for many startups, SMEs and public listed companies. He has helped many companies integrate AI-based workflow automations across functional units, and developed conversational AI interfaces that enable users to interact with systems through natural dialogue.