Impact: Democratizes voice AI evaluation for product managers and researchers while driving industry transparency through objective benchmarks
Every product manager faces the same dilemma: which AI voice provider should we use? OpenAI's Whisper? Deepgram's Nova? Google's Gemini? The wrong choice costs time, money, and user trust.
The typical testing workflow is broken. You copy text into one provider's dashboard, generate audio, download it, and listen. Then repeat for every provider. Comparing results side-by-side? Nearly impossible. Testing how well generated speech transcribes back to text? Forget about it. For non-technical users, this makes informed decisions nearly impossible.
VoiceArena changes this. It's a free, open-source platform that lets anyone compare text-to-speech (TTS) and speech-to-text (STT) models from 7+ providers simultaneously — no coding required. Test multiple models in parallel, get real accuracy metrics (Word Error Rate, Character Error Rate), compare costs transparently, and validate round-trip performance where speech generation and transcription work together.
Built for product managers, AI researchers, and content creators who need to evaluate voice AI without wrestling with API complexity or building custom testing infrastructure.
The voice AI market is exploding. Text-to-speech is projected to grow from $2.96 billion in 2024 to $9.36 billion by 2032, driven by a 15.5% compound annual growth rate. Multiple sources forecast the market reaching $12.4 billion by 2033.
This growth has created an explosion of providers: OpenAI, Deepgram, ElevenLabs, Google Gemini, Mistral, AssemblyAI, and more. Each claims superior quality. Each has different pricing models. Each excels at different use cases.
The problem? Quality assessment traditionally requires technical expertise. Academic frameworks like Mean Opinion Score (MOS) benchmarks and CNN-LSTM naturalness evaluation models aren't accessible to most decision-makers. Product teams need systematic evaluation tools that democratize model comparison — letting them make data-driven choices based on objective metrics rather than marketing claims or convenience.
VoiceArena began three months ago as an independent study with Prof. Rohit Aggarwal. His vision was clear: create an accessible testing portal that democratizes voice evaluation for non-technical users. The initial concept was modest — a simple comparison tool for two STT models.
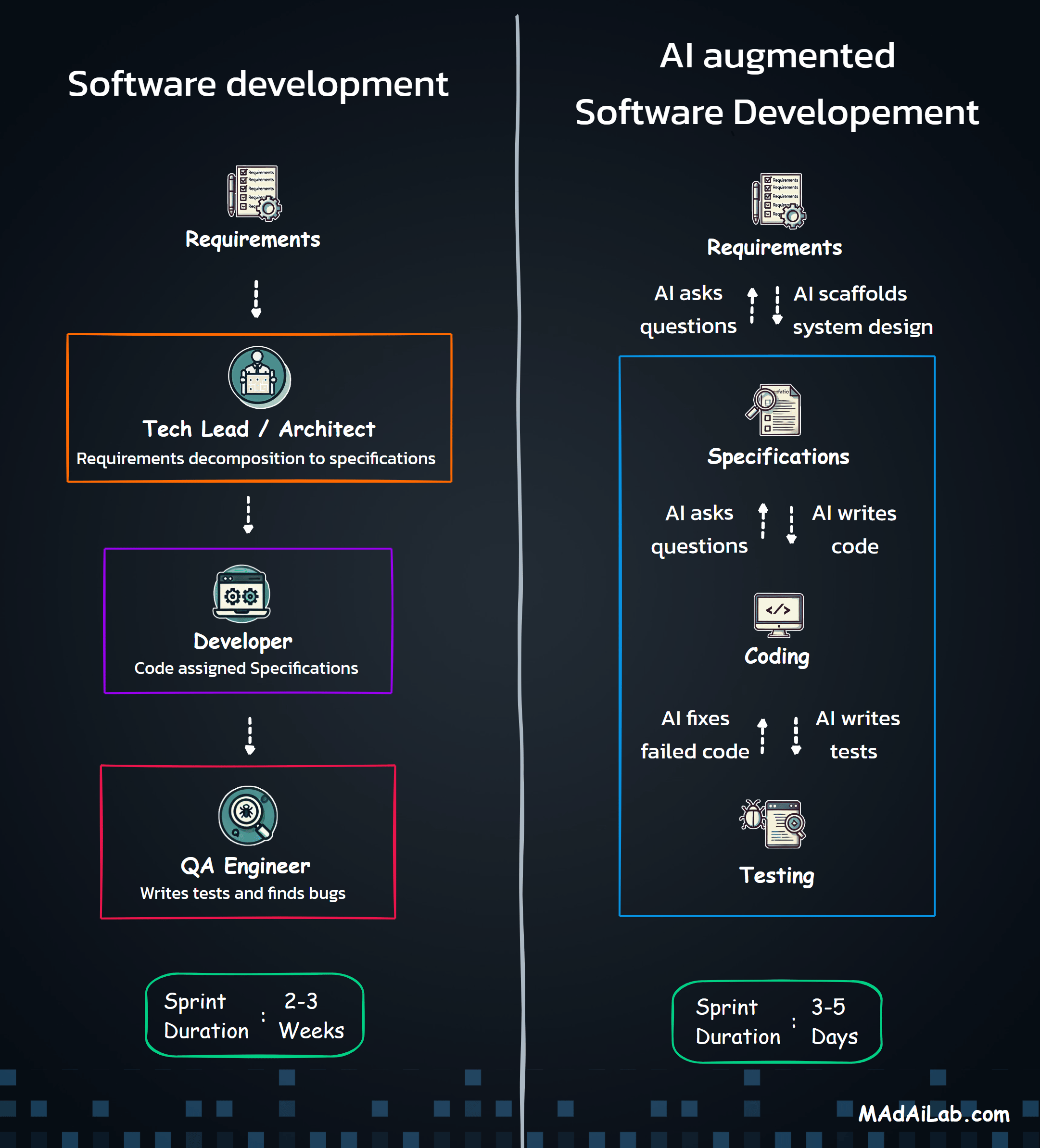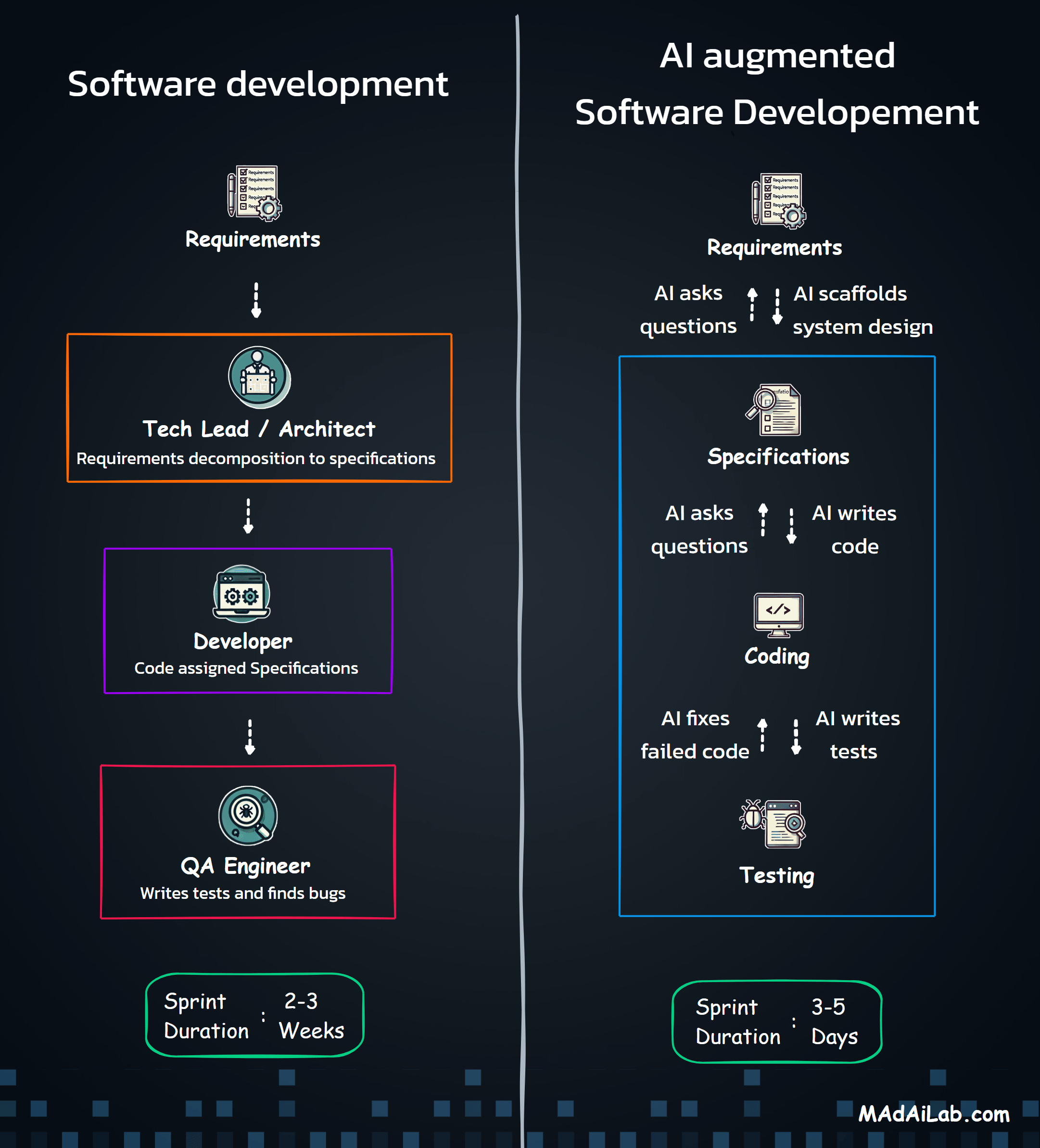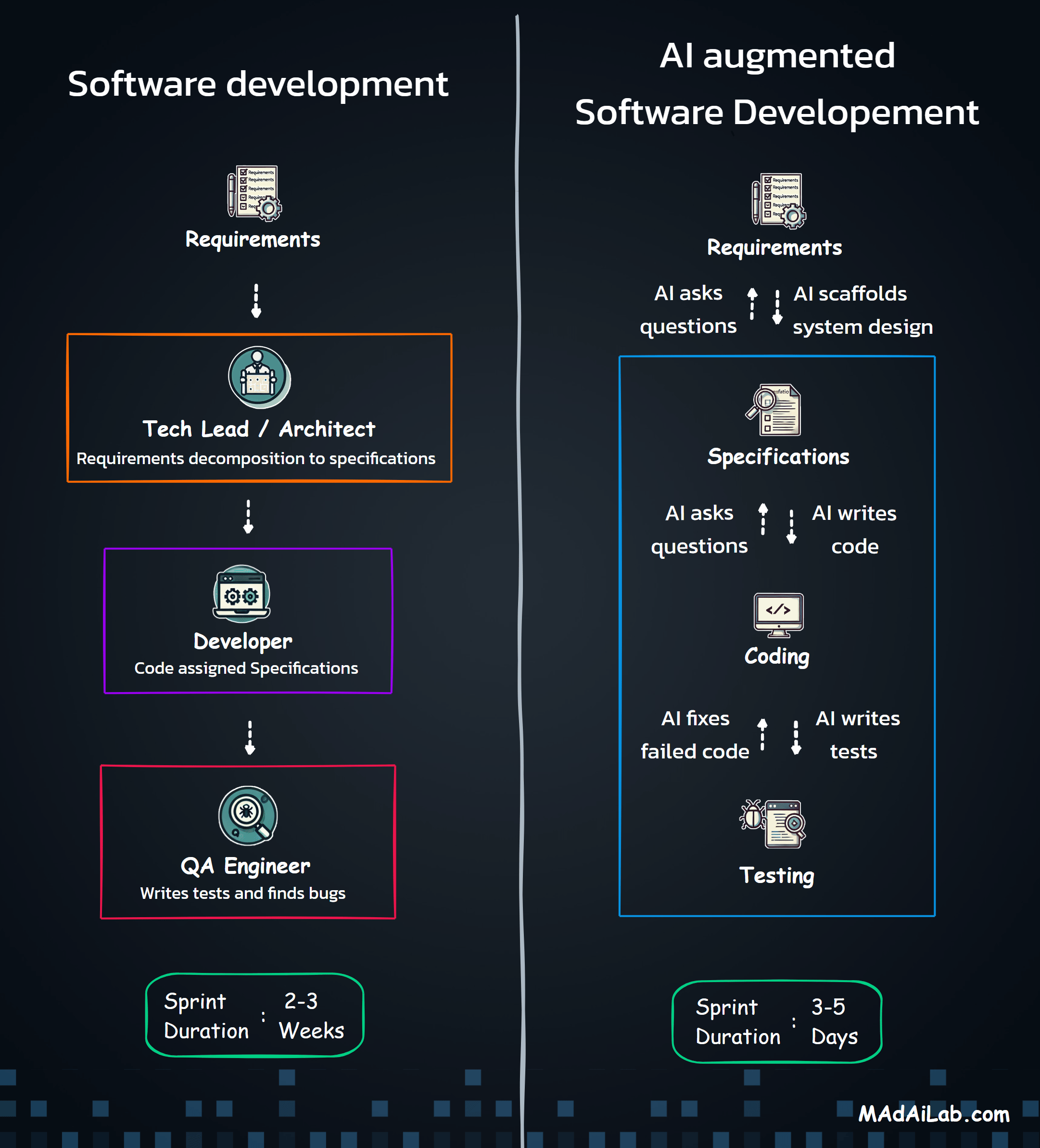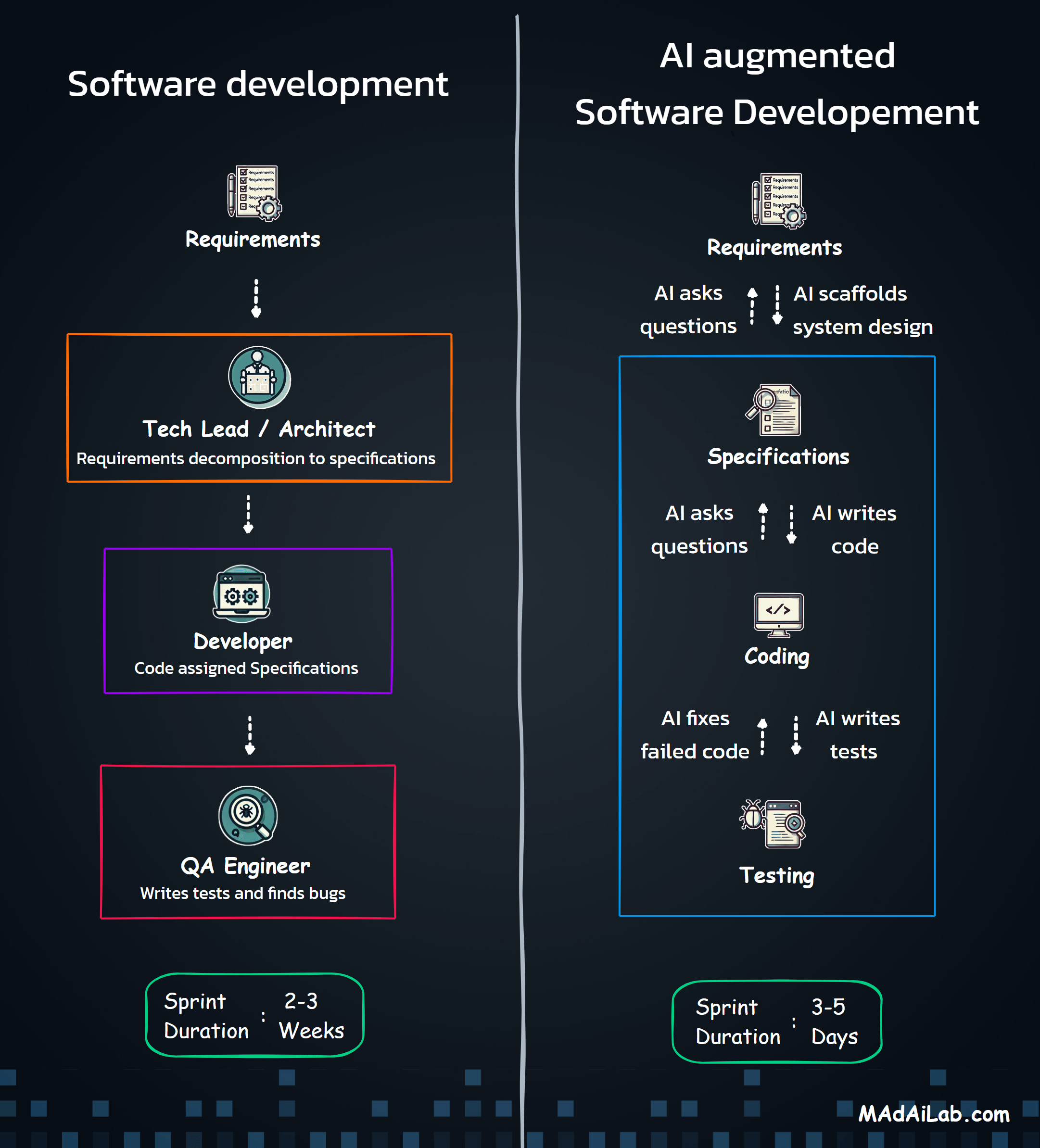
The project evolved rapidly through iterative development cycles. Month one focused on core transcription testing with two models. Month two expanded to multiple STT providers with parallel processing architecture, growing to support seven major providers simultaneously. Month three added TTS generation capabilities, the round-trip workflow that tests both directions, and leaderboard analytics for performance rankings.
What started as an independent study transformed into an open-source project with continuous development. New models are added regularly, and the platform now serves researchers, product teams, and developers evaluating voice AI at scale.
Throughout development, Prof. Aggarwal provided conceptual guidance that shaped the platform's direction, while I handled all technical implementation and architecture. We consulted extensively with product managers to validate real-world use cases, ensuring the platform solved actual problems rather than theoretical ones. Quality assurance relied on manual testing and blind testing — comparing results without knowing which provider generated them to eliminate bias.
The technical challenges were substantial. Parallel provider processing required handling seven different API formats simultaneously with isolated error handling. Implementing industry-standard WER and CER algorithms accurately demanded validation against research benchmarks. Vercel's serverless limits, audio format conversions across providers, and rate limiting all presented obstacles.
The breakthrough came with session management architecture. This single insight made everything stable and controllable — enabling reliable experiment tracking across pages, supporting the round-trip workflow, and maintaining data integrity throughout complex user journeys. It transformed the platform from a fragile prototype into production-ready infrastructure.
The research foundation draws on established frameworks: CNN-LSTM architectures for TTS naturalness evaluation, MOS benchmarks where scores above 4.0 indicate near-human quality, and industry-standard WER/CER metrics that provide objective accuracy measurements independent of subjective human ratings.
The Listener page handles speech-to-text evaluation. Upload an audio file or record directly in your browser using the built-in recorder. Select which STT models to test — OpenAI's Whisper, Deepgram Nova-3, Google Gemini, Mistral Voxtral, or any combination. Click transcribe.
The platform processes all selected models in parallel and displays results side-by-side: the transcription text, accuracy scores if you provided ground truth, processing time, and cost per minute. Word Error Rate and Character Error Rate give you objective quality measurements. Cost analysis shows exactly what you'd pay each provider.
Use case: Which STT model best handles your specific accent, audio quality, or technical vocabulary? Run the same audio through five models and see the difference immediately.
The Speaker page generates synthetic speech. Enter your text and select TTS models — OpenAI's six voices, Deepgram Aura's eight voice models, or ElevenLabs' options. Click generate.
Within seconds, you hear all the voices side-by-side. Play, pause, download, or compare audio quality directly. The platform shows generation time and cost per character for each provider.
The key innovation: one-click transfer to transcription testing. Generate speech and immediately send it to the Listener page for round-trip validation.
Use case: Does your generated speech transcribe accurately back to the original text? This reveals real-world performance beyond just “does it sound good?”
The Leaderboard page aggregates performance data across all tests. Models rank by accuracy, processing speed, cost, and overall rating. Visual quadrant analysis charts plot cost versus WER, speed versus accuracy, helping identify the best value for your specific requirements.
Filter by provider, features, or status. The leaderboard answers: What's the optimal model for my budget and quality needs?
This workflow reveals what other testing platforms miss. Generate speech on the Speaker page with your chosen TTS model. The system stores the original text as ground truth. Click "Transcribe" and the audio automatically transfers to the Listener page.
Now run it through multiple STT models. The platform calculates how accurately the transcription matches your original text — measuring real-world accuracy loss through the complete cycle. A perfect TTS model that produces hard-to-transcribe speech isn't actually perfect. Round-trip testing exposes this.
The architecture handles complex requirements while maintaining simplicity for users. Parallel processing tests seven providers simultaneously without cascading failures — if one API times out, the others continue unaffected. Each provider lives in an isolated error boundary.
Industry-standard metrics provide credibility. The WER calculation uses the Levenshtein distance algorithm validated against academic research: (Substitutions + Insertions + Deletions) / Total Words. CER measures character-level accuracy. Both metrics enable objective comparison across providers without relying on subjective human judgment.
The infrastructure adapts to different deployment scenarios. Production deployments use MongoDB for experiment tracking and AWS S3 for audio storage. Quick testing runs entirely in-memory without external dependencies. The session management system tracks experiments across pages using unique identifiers, maintaining data integrity through complex workflows.
The "Bring Your Own Keys" model matters for transparency. The platform itself is completely free and open-source with no fees or markup. Users provide their own API keys and pay providers directly at standard published rates. An optional coupon system enables quick experiments without API setup for demos and trials. Every test shows exact costs before running, eliminating surprises.
VoiceArena addresses a transparency gap in the voice AI market. When model selection is difficult, decisions default to convenience — whichever provider you already use, or the one with the best marketing. Quality takes a backseat to familiarity.
Systematic comparison raises the bar. Product managers can demand proof of performance before committing. Researchers get reproducible benchmarks. Content creators optimize for their specific use cases — audiobook narration requires different qualities than customer service bots.
Providers benefit too. Objective benchmarks reward actual quality improvements over marketing claims. The best models rise in the leaderboard through performance, not persuasion.
Building this platform taught hard lessons. Session management emerged as the architectural cornerstone — the insight that made complex workflows stable and reliable. Product manager feedback shaped practical features over technical sophistication; real users don't care about elegant code, they care about solving their evaluation problem efficiently.
Blind testing revealed edge cases automated validation missed. When you don't know which provider generated a result, you evaluate quality honestly. Some providers excelled at clear speech but struggled with background noise. Others handled accents well but faltered on technical terminology. These insights only emerged through systematic, unbiased testing.
The open-source approach enables community-driven improvement. As new models launch, contributors can add them quickly. As evaluation techniques improve, the community can enhance the metrics. No single company controls the benchmarks — the transparency is structural, not optional.
VoiceArena is publicly available at github.com/mentorstudents-org/VoiceArena. The platform remains under active development with new models added regularly as providers release updates.
Community contributions are welcome. Whether adding new provider integrations, improving accuracy algorithms, enhancing the UI, or expanding documentation — the open-source model thrives on diverse perspectives.
The key takeaway: voice AI evaluation no longer requires technical expertise or custom tooling. Systematic comparison enables better decisions and drives industry-wide quality standards. Transparency benefits everyone — users get better products, providers compete on merit, and the market moves toward objective quality rather than marketing noise.
I am a Data Scientist with 5+ years of experience specializing in the end-to-end machine learning lifecycle, from feature engineering to scalable deployment. I build production-ready deep learning and Generative AI applications , with expertise in Python, MLOps, and Databricks. I hold an M.S. in Business Analytics & Information Management from Purdue University and a B.Tech from a B.Tech in Mechanical Engineering from the Indian Institute of Technology, Indore. You can connect with me on LinkedIn at linkedin.com/in/mayankbambal/ and I write weekly on medium: https://medium.com/@mayankbambal
Dr. Rohit Aggarwal is a professor, AI researcher and practitioner. His research focuses on two complementary themes: how AI can augment human decision-making by improving learning, skill development, and productivity, and how humans can augment AI by embedding tacit knowledge and contextual insight to make systems more transparent, explainable, and aligned with human preferences. He has done AI consulting for many startups, SMEs and public listed companies. He has helped many companies integrate AI-based workflow automations across functional units, and developed conversational AI interfaces that enable users to interact with systems through natural dialogue.
Prof. Rohit Aggarwal — Conceptual vision for democratizing voice AI evaluation and strategic guidance throughout the platform's development journey
MAdAiLab — API cost sponsorship and infrastructure support that enabled extensive provider testing across multiple models
Product Manager Community — Real-world use case validation and feature prioritization feedback that shaped practical functionality
Verified Market Research. (2024). Text To Speech (TTS) Market Size, Share, Trends & Forecast. Projected market growth: $2.96B (2024) to $9.36B (2032) at 15.5% CAGR.
Tags: #VoiceArena #OpenSource #TextToSpeech #SpeechToText #AIVoiceModels #VoiceAI #ModelComparison #ProductManagement #AIResearch #MAdAILab